
Passa dai dati, dal loro utilizzo, dalla loro valorizzazione e dall’arricchimento con elementi di Intelligenza Artificiale il percorso di modernizzazione delle imprese.
Ne è convinta IBM, che proprio al connubio tra Dati e Artificial Intelligence ha dedicato un evento in diretta streaming, Data & AI Summit, che si è svolto lo scorso 29 aprile e al quale hanno partecipato 36 relatori, coinvolti, in una lunga diretta di oltre 5 ore, non solo dall’Italia ma anche da Spagna, Lettonia e Stati Uniti.
Un evento organizzato in una sessione plenaria e in due sessioni parallele, nel quale si è voluto esplorare, anche con la testimonianza di casi utenti, tutto il potenziale che dai dati deriva.
Data & Ai Summit: un percorso in quattro tappe per liberare il potenziale dei dati
È stato Alessandro La Volpe, Vice President Cloud &Cognitive Software, IBM Italia a definire lo scenario: “La raccolta, l’organizzazione evoluta dei dati e l’Intelligenza Artificiale sono il mezzo per la trasformazione digitale delle aziende. Ma per raggiungere gli obiettivi fissati è necessaria una Data Strategy. È necessario un approccio quasi sistemico alla gestione dei dati”:
Un approccio che Alessandro La Volpe definisce come un percorso, un viaggio in quattro tappe, o, secondo la visione di IBM, una scala composta di quattro gradini.
Fil rouge di tutto l’evento è stata in effetti la cosiddetta “AI Ladder”, nella quale sono definiti i quattro passaggi imprescindibili per una corretta data strategy.

Il primo livello è rappresentato dalla fase di raccolta dei dati, “Collect”, per la quale il criterio fondante è rappresentato dalla loro accessibilità, cui fa seguito la fase di organizzazione, “Organize”, dei dati. È una fase importante, nella quale già si fa strada quel concetto di data quality indispensabile per lavorare sui dati giusti per poterne trarre le giuste indicazioni di business.
La terza fase, ovvero il terzo gradino della scala, è rappresentato dall’analisi dei dati, “Analysis”, necessaria per poter finalmente avvicinare il grande tema dell’Intelligenza Artificiale. È alla fine di questo percorso che si arriva finalmente alla fase di arricchimento, che IBM definisce di “Infuse”, nella quale l’Intelligenza Artificiale arricchisce i dati, facendone veri e propri abilitatori di cambiamento e opportunità di business.
IBM accompagna i suoi clienti e partner in questo viaggio con la propria proposition, rappresentata da IBM Cloud Pak for Data, una piattaforma dati e AI integrata, che dunque copre tutte le fasi di raccolta, organizzazione, analisi e “infusione” di intelligenza Artificiale dei dati, basata non solo su IBM Watson, ma su uno stack importante di tecnologie, come RedHat OpenShift Container e la Hybrid Data Management Platform.
Implementabile in brevissimo tempo ed estensibile con un ventaglio di microsoervizi in costante aumento, IBM Cloud Pak for Data funziona su qualsiasi cloud, a partire da quello di IBM, naturalmente, e consente di accelerare i percorsi di innovazione delle imprese senza impattare negativamente sui TCO.
A dimostrazione di come questa strategia Possa trovare riscontro in un caso reale, arriva la testimonianza di AutostradeTech, con il suo Amministratore Delegato Lorenzo Rossi, che parla del progetto Argo 2019, per il monitoraggio di ponti e viadotti, per il quale le tecnologie IBM vengono utilizzate per le attività di raccolta, razionalizzazione, classificazione dei dati.
“È un progetto nel quale entrano in gioco tematiche di Governance e di Asset Management, e che di fatto racchiude tutto il tema di piattaforme e strategia di questa giornata”, chiosa La Volpe.
Governance sui dati, un tema complesso
C’è comunque consapevolezza della complessità del tema. E lo spiega nel suo intervento Giovanni Boccia, Technical Sales Manager – Information Architecture IBM: “I dati sono la base per qualunque iniziativa di Business Intelligence o di Artificial Intelligence che una azienda voglia intraprendere – spiega – ma dobbiamo essere consapevoli che spesso i dati sono di difficile accesso, non sempre affidabili, difficili da integrare. Per questo non ci si può fermare alla loro raccolta: serve sempre un lavoro di pulizia e di data quality prima di poter passare alle fasi successive”.
La dimostrazione viene anche in questo caso da una situazione reale e quantomai attuale, rappresentata dalla testimonianza di Giuseppe Preziosi, Responsabile del Data Warehouse e Business di Aria Regione Lombardia.
Con Preziosi si parla infatti di gestione dei dati sanitari: è il suo dipartimento che ha la responsabilità di fornire tutti i giorni i dati sull’epidemia Covid-19. È facile intuire la delicatezza della situazione: si tratta di dati sensibili, dati sanitari, provenienti da fonti eterogenee, caricati su un sistema analitico ad alte prestazioni, per i quali è indispensabile una Governance rigorosa.
Una criticità che Aria affronta e gestisce con il supporto delle tecnologie IBM.
Da DevOps a DataOps
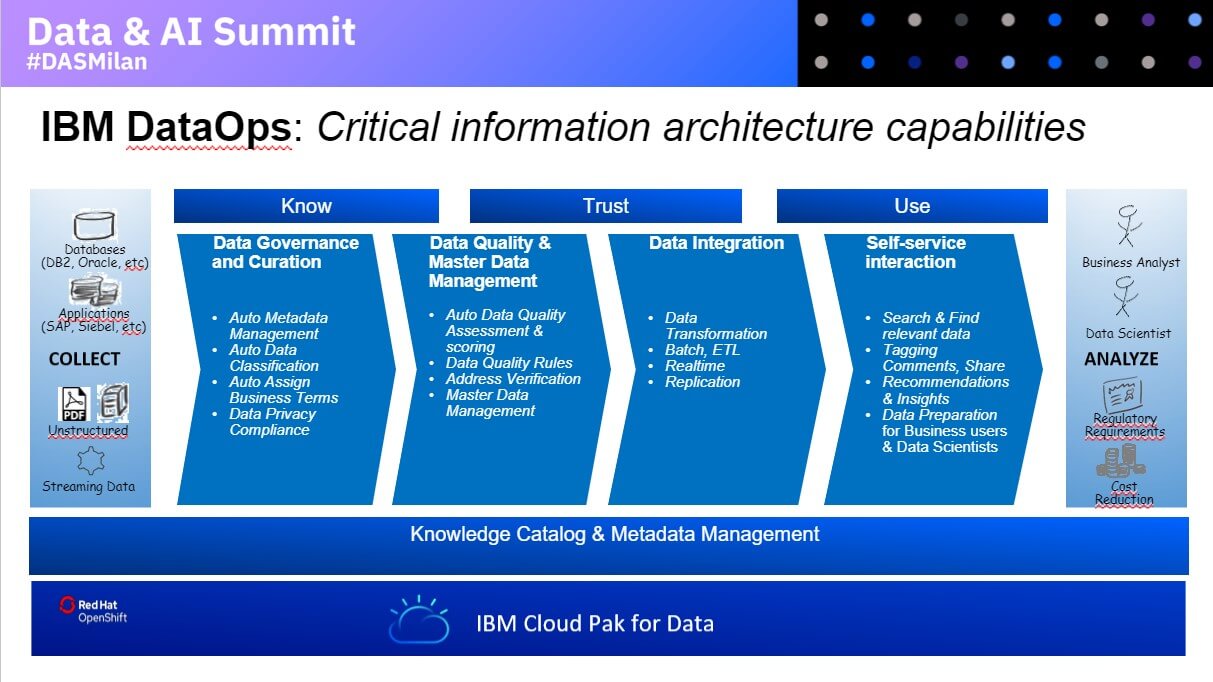
Ma tocca a Massimo Teratone, IBM Data & AI Information Architecture Tech Sales introdurre un elemento tecnologico fondamentale nella data strategy fin qui disegnata: DataOps.
“Fare DataOps, ovvero Data Operation, significa comprendere i dati, capirne il significato, scoprire ad esempio la presenza di dati personali all’interno dei dataset, significa rendere i dati affidabili, significa affrontare il tema della data quality. Significa rendere, in altre parole, i dati pronti alla fase successiva ovvero quella dell’utilizzo”.
Sullo stesso tema si sofferma anche Najla Said, Data Science Squad Manager.
“Stiamo mutuando nei dati le best practice del DevOps. Passare a Data Ops, ovvero alle Operation dei dati significa portare una metodologia di lavoro pensata per lo sviluppo applicativo, anche nello sviluppo di applicazioni che lavorano sui dati”.
In effetti è proprio Najila Said che si occupa del terzo gradino della scala ideale, l’Analyze.
“Estrarre valore dai dati in modo affidabile è complicato, bisogna creare dei processi che nei loro step riproducano una metodologia di ricerca rigorosa. È un processo iterativo, il learning deve essere continuo e aggiornato; si producono applicazioni che dipendono dal feedback che ricevono, i modelli devono essere costantemente ritoccati: per questo serve una architettura flessibile, in grado di coprire l’end to end e soprattutto robusta. Serve una piattaforma che contenga sia i tool cari ai data scientist, sia tutti quegli strumenti di più alto livello che consentono di comunicare gli insight traducendoli verso il business. Servono dati ben curati, verificati, sottoposti al controllo di qualità”.
Quanto alle declinazioni “di mercato”, Najila Said non ha dubbi: “Le sperimentazioni che abbiamo già in campo abbracciano tutte le industry, banche, assicurazioni, trasporti, manifattura… con casi d’uso molteplici, dalla visual recognition agli studi predittivi, dalla sensoristica all’ottimizzazione logistica”.
Su tutto questo si innesta anche un tema di agilità, indispensabile quando si parla di data science. Anzi, per Najila Said l’agilità “è proprio il senso della data science: senza capacità di trasformazione è fallace. Faccio un esempio concreto. Per uno nostro cliente stavamo effettuando uno studio sulla mobilità dei dipendenti, utilizzando dati storici legate alla presenza in sede, alle condizioni meteo, alla situaizone dei trasporti. Poi, con l’insorgenza dell’emergenza Covid-19, l’obiettivo è cambiato: ora gli insight servono per organizzare al meglio la fase 2. Questo dimostra quanto i progetti data science abbiano bisogno di flessibilità.
Al di là delle due testimonianze di Autostrade e Aria, cui nel corso della mattinata si aggiungeranno anche quelle di Bartolini, MPS, PikDare e Inail, non v’è dubbio che vi sia comunque una certa difficoltà a portare in produzione le sperimentazioni o i PoC.
Quali ostacoli nel portare l’AI nelle imprese?
È Francesco Basciani, Strategy Consultant e Data Scientist che analizza i motivi per i quali ad oggi molte aziende non riescano ad applicare nei loro business l’Intelligenza Artificiale. “Sostanzialmente per tre problemi. Il primo è il know how, ovvero le scarse competenze e conoscenze tecniche, matematiche…, il secondo è rappresentato dalla tecnologia, ovvero dalla necessità di una infrastruttura adeguata, il terzo è rappresentato da problemi di natura regolatoria”.

A questo stato di cose IBM risponde con la metodologia Garage, che accompagna le imprese in sessioni di analisi, di design thinking, fino alla realizzazione di un MVP, minimum viable product, con i servizi IBM Watson Studio, Machine Learning e Open Scale, “e con un focus molto chiaro sul tema della explainability, che porta alla possibilità di spiegare perché l’intelligenza artificiale ha preso determinate decisioni”.
Infuse: ovvero come l’AI potenzia la Digital Transformation
La quarta e ultima fase, ovvero l’ultimo gradino della scala, è rappresentato da Infuse, ovvero dall’infusione di elementi di Intelligenza Artificiale nei dati.
“Tutto parte dai dati, i dati sono la base per guidare le decisioni aziendali intelligenti”, esordisce Davide Fratus, Technical Sales Manager Data&AI – . I dati sono ciò che sblocca la digital transformation nelle aziende, ma è l’AI che ne sblocca il valore. È vero, i tassi di adozione sono un po’ più lenti del previsto, ma le soluzioni IBM e la piattaforma IBM Cloud Data Pak aiutano le imprese a velocizzare l’adozione dell’AI, che arricchisce tutti i verticali e tutti i settori di industria”. Si va dal mondo bancario, che con l’AI è in grado di potenziare i propri percorsi di digital transformation, al mondo delle Telco, che ne beneficiano sia nell’ambito dell’assistenza clienti sia in quello della gestione operativa. Per non tacer delle soluzioni di pianificazione e controllo di gestione (forecasting), dello sviluppo di modelli di previsione finanziaria, della gestione credito.
“Ci sono realtà che devono operare in ambienti regolamentati, compliant, devono monitorare i fattori di rischio e usare gli strumenti di reporting: in questo caso l’infusion di intelligenza artificiale consente di affrontare meglio tematiche come la gestione del rischio operativo, la compliance o l’antifrode, con la possibilità di gestire domande in linguaggio naturale”.
A sua volta Bianca Romano, Dev Squad Manager, cita ulteriori ambiti di applicazione, come tutto il mondo dell’intelligent engagement. “La cosa più importante – sottolinea – è che tutti utilizzano le stesse tecnologie, declinandole in modo diverso”.
Il cuore di tutto ciò di cui si sta parlando, per Bianca Romano è rappresentato dal knowledge management, dalla capacità di gestire grandi moli di dati non strutturati anche grazie all’intelligent automation, all’automazione intelligente.
La declinazione IBM: Watson e i suoi servizi
Naturalmente, al centro di tutto ciò di cui si parla e si è parlato ci sono Watson e i suoi servizi. È Simona Pondrano, Data & AI Technical Sales, che li inquadra con sistematicità e precisione.
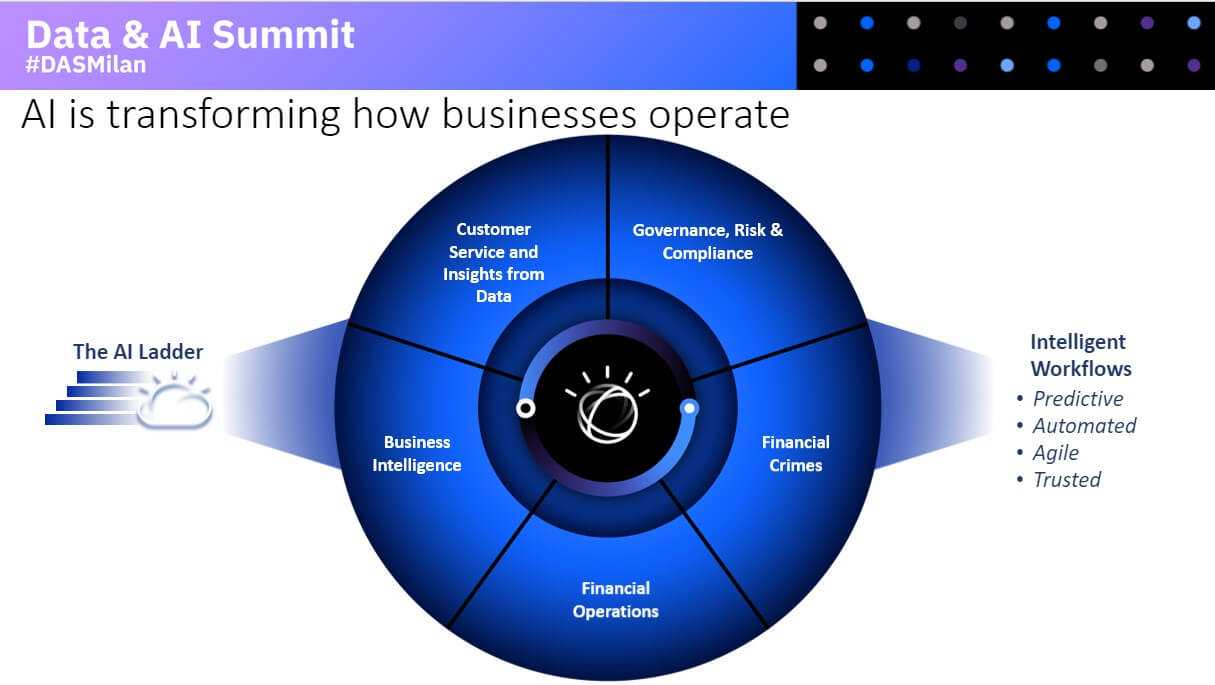
“L’intelligenza Artificiale cambia il modo con cui le imprese lavorano. Arricchisce e supporta la Business Intelligence, con Cognos Analytics; il Customer Service, con i Watson Services; l’area Finance, con Planning Analytics; il fronte GRC, Governance Risk e Compliance, con OpenPages; e ancora nel contrasto ai crimini finanziari con Financial Crimes Insight. Tutto questo introducendo dei workflow intelligenti, ovvero predittivi, automatizzati, agili e affidabili”.
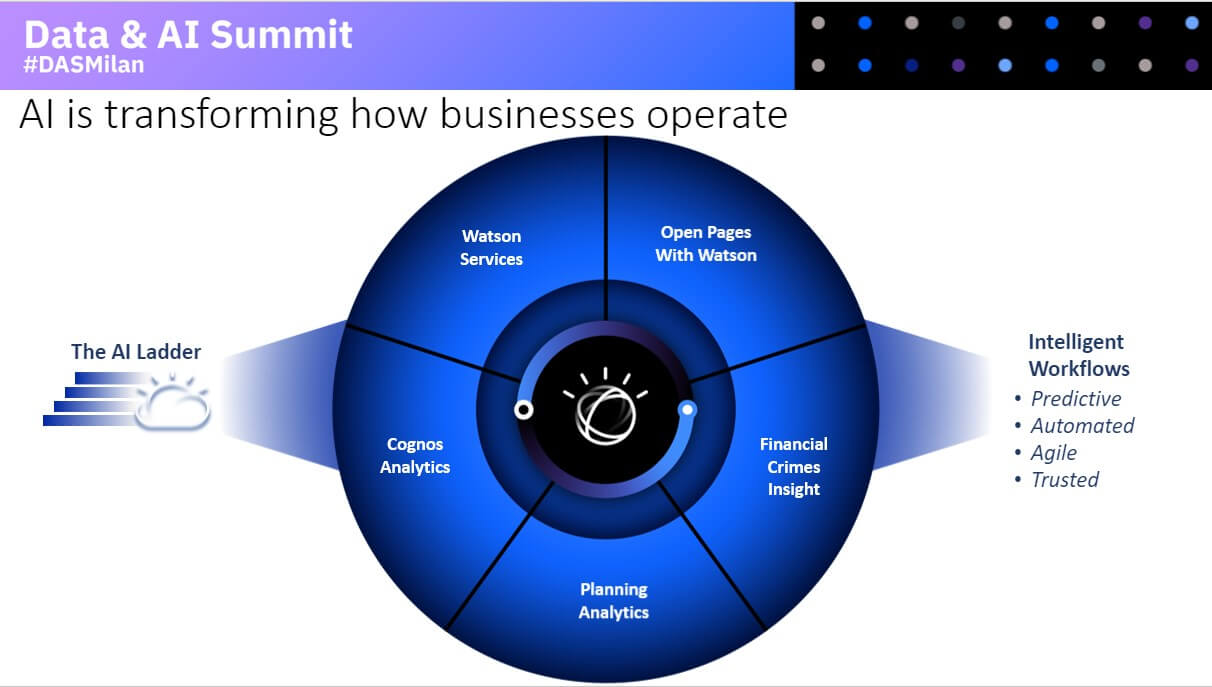
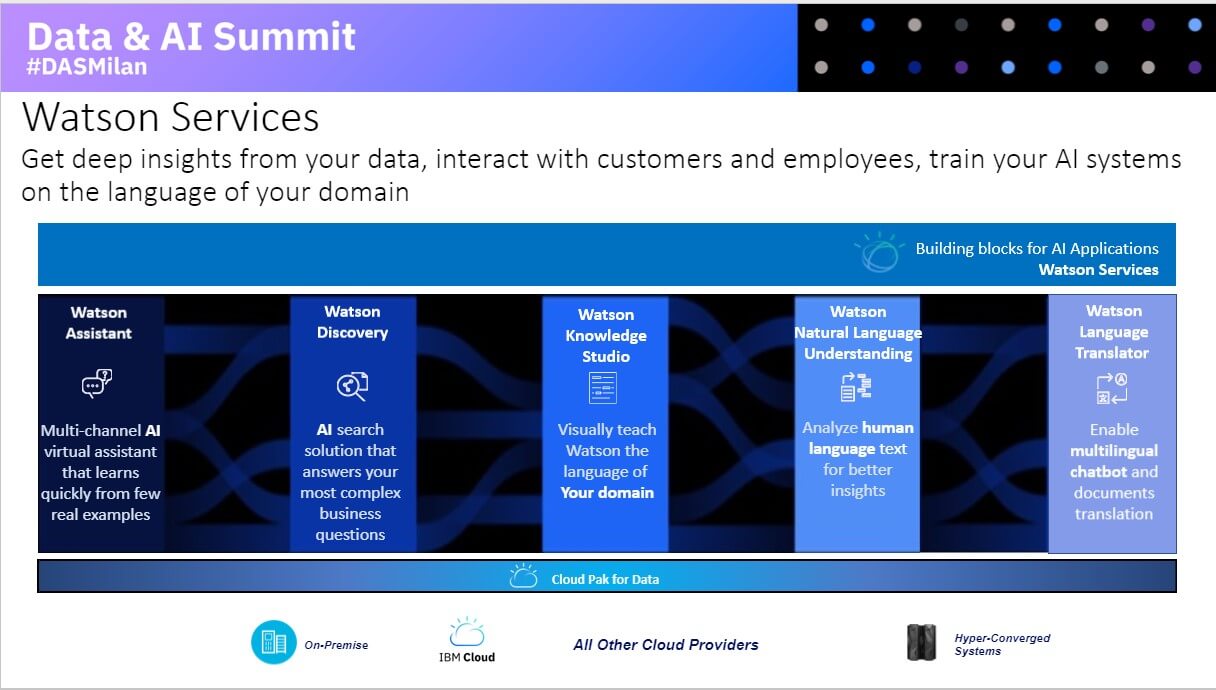
Da ultimo Simona Pondrano presenta una carrellata proprio sui servizi Watson, evidenziandone le declinazioni. Si parte con Watson Assistant, un virtual assistant mutlicanale, Watson Discovery, soluzione per la ricerca all’interno di data set complessi, Knowledge Studio, per l’apprendimento dei linguaggi specifici dei diversi business, Natural Language Understanding, per la comprensione del linguaggio naturale e Language Translator per la realizzazione di chatbot multilingua.
Il ruolo di IBM Garage
È questo l’intervento che ha di fatto chiuso la sessione plenaria. Prima dell’apertura delle sessioni parallele, nel corso delle quali tutti questi temi sono stati ripresi e approfonditi anche con sessioni di demo live, non poteva però mancare uno spazio dedicato a IBM Garage e al suo ruolo all’interno dell’ecosistema IBM.
Lo hanno spiegato Francesca Guccione, Practive Manager IBM Garage e Silvia Peschiera, IBM Garage Client Expert Leader.
Il Garage di IBM è una delle 17 strutture che IBM ha costituito in tutto il mondo a supporto dei percorsi innovazione e modernizzazione delle imprese.
“Mai come in questo periodo – ha spiegato Francesca Guccione – le imprese hanno bisogno di vantaggi competitivi per restare sul mercato e devono automatizzare i loro processi. Ci chiedono aiuto per innovare, per usare le nuove disruptive technologies, come AI, Blockchain, IoT, per modernizzare, per il move to cloud, i microservizi. Con Garage li aiutiamo in un percorso o metodologia che parte da una fase di ingaggio di tre ore, nella quale vengono identificate le opportunità di business, per poi passare alla fase di design thinking, che dura circa una settimana, con 2 giorni in compresenza con il cliente, ai workshop infrastrutturali fino ad arrivare agli MVP (minimum viable products). Caratteristica di questa progettualità è la velocità: tutto non deve durare più di dieci settimane”.
Da giugno dello scorsso anno, hanno avuto accesso a IBM Garage 250 clienti di settori molto diversi tra loro.
“In considerazione del momento che stiamo attraversando, anche IBM Garage è diventato del tutto digitale: le parole chiave restano le stesse, quello che cambia sono gli strumenti, ancora più orientati alla collaboration e all’interazione”.
Una delle fasi più importanti della metodologia Garage è la Business Framing Session, ovvero la fase di identificazione delle opportunità di business.
“Si tratta di un workshop – spiega Silvia Peschiera – nel quale collaboriamo e co-creiamo con i nostri clienti per identificare le opportunità che hanno in mente. Il workshop ha una durata di circa tre ore, necessarie per pianificare poi lo sviluppo del progetto. Vi devono prendere parte i decisori di business e gli owner del processo che si va a migliorare. In questo momento siamo pronti a disegnare con i clienti strategie che vadano oltre la criticità del momento, così da essere pronti per il futuro”.
Puoi rivedere tutte le sessioni dell’evento a questi link
Sessione Plenaria
Sessione Parallela 1 (Collect-Organize-Analyze)
Sessione Parallela 2 (Infuse)
















