In ambito data analytics, la data preparation permette di raggiungere una buona qualità dei dati. Disporre di una buona data quality e gestire i dati in maniera conforme alle normative sono prerequisiti indispensabili nella scelta degli strumenti per implementare strategie data-driven in azienda.
Insieme al data catalog e al data modeling, la data preparation è inoltre un elemento cruciale nella data virtualization. Ecco cos’è e a cosa serve la preparazione dei dati, il pilastro su cui si fonda un’efficace data governance.
Indice degli argomenti
Cos’è la data preparation
La data preparation è la disciplina dedicata a preparare i dati all’uso in ambito data analytics. Infatti, una volta puliti e organizzati, i dati sono pronti per la fase di analisi. La preparazione dei dati permette di operare agilmente sui dataset, risparmiando tempo.
La preparazione dei dati consente di migliorare la qualità generale e offrire dunque una migliore data quality, semplificandone l’accessibilità. Insieme a data governance, fa parte degli strumenti di data management. Superiore è la complessità dei dati, più tempo richiedono le attività preliminari all’analisi. Il motivo è anche da attribuire alle norme da seguire sul trattamento dei dati.
La data preparation permette di raccogliere, strutturare, integrare tramite combinazioni e organizzare i dati, in modo tale da darli in pasto all’analisi descrittiva in ambito Business Intelligence o renderli fruibili all’analisi predittiva e prescrittiva, in area Business Analytics.
Nell’ambito del self-service data analytics, e dunque in ambito democratizzazione degli strumenti di analisi, inoltre, le analisi diventano alla portata di tutti. La self-service data preparation punta a fornire agli utenti le abilità per modificare i dati, preparandoli al meglio per le presentazioni.
La data preparation è infine anche un tassello che, insieme al data catalog e al data modeling, compone il mosaico della Data virtualization.

In ambito virtualizzazione dei dati
La virtualizzazione dei dati consente alle imprese l’accesso ai dati, ovunque risiedano e comunque siano composti. Essa offre inoltre una visione unificata dei dati in modo più rapido, conveniente e dispendioso, sotto il profilo delle risorse rispetto agli approcci classici all’integrazione dei dati.
La Data virtualization agevola, dunque, l’adozione del Logical data fabric, automatizzando numerose funzioni di gestione dei dati tramite l’uso di intelligenza artificiale (AI) e machine learning (ML). Fornisce anche ulteriori funzionalità semantiche proprio attraverso la data preparation, unitamente alle altre componenti della virtualizzazione dei dati, quali il data catalog e il data modeling. Ha anche il ruolo di ridurre la complessità ai team IT e di data engineer che si dedicano a gestire i processi ETL (processi di Extract, Trasform and Load).
I vantaggi principali della data virtualization consistono nell’offrire flessibilità e agilità organizzativa e soddisfazione dei dipendenti e dei clienti. Inoltre offre benefici in termini di compliance, sicurezza e governance. Permette quindi di gestire autorizzazioni e ruoli nell’ambito dell’organizzazione, proteggendo i dati in conformità in modo più semplice.

Step di preparazione
Secondo gli Osservatori Big Data del Politecnico di Milano, il data scientist destina l’80% del tempo alla preparazione e alla pulizia dei dati.
L’avvento dei big data e delle 5V (volume, varietà, velocità, veridicità, variabilità) ha radicalmente innovato i processi di manipolazione e data analytics. L’introduzione del GDPR, il Regolamento europeo sulla protezione dei dati personali, ha inoltre richiesto maggiore attenzione sul trattamento dei dati, da parte di chi e con quali scopi.
La data preparation, dunque, è un processo articolato, ma fondamentale per assicurare una qualità dei dati tale da agevolare l’estrazione dei dati di valore. Nell’era dei big data si tratta infatti di approcci che aiutano a sfruttare al meglio l’ammontare di dati a disposizione, per consentire ai decision-maker di prendere decisioni sempre più data-driven. Ecco quali sono gli step di preparazione, che punta a rendere i dati, una volta puliti e organizzati, pronti per la vera e propria fase di analisi.

Data gathering
La raccolta dei dati rappresenta il primo step della data preparation. Il data gathering raccoglie i dati da numerosi fonti: sensori IoT, data warehouse, data lake, database, ERP, feed dei siti web eccetera.
Ma oggi sempre più l’acquisizione dei dati avviene da dataset esterni. In questa fase il data scientist sottopone i dati a verifiche per monitorare e testare le funzionalità rispetto all’uso e alle finalità richieste.

Data discovery
Con l’esplorazione dei dati, la data preparation entra nella seconda fase. La data discovery, infatti, permette di esplorare i dati racconti, per capire con precisione come ottimizzarli in maniera adeguata secondo l’uso previsto.
La data discovery, complementare alla profilazione dei dati, permette di individuare incongruenze, eventuali anomalie, attribuzione di dati e assenza metadati oltre ad altre criticità presenti nei dataset. L’obiettivo è risolvere le problematiche prima di procedere agli successivi step di preparazione. La data discovery punta ad acquisire consapevolezza dei contenuti dei dataset disponibili.
Solo una puntuale e chiara definizione dei problemi e necessità che l’analisi ha come obiettivo, può avviare il processo di analisi in maniera corretta. Individuare i desiderata e il valore che la data analytics deve estrarre per il business: è la fase che orienta gli step successivi che stanno a valle;.
Selezionare le corrette sorgenti dati (o parti di esse) da prendere in esame, quali informazioni ottenere in questo perimetro informativo e come comunicare i dati rappresentano il passaggio essenziale per scegliere la metodologia migliore e gli opportuni strumenti da impiegare.
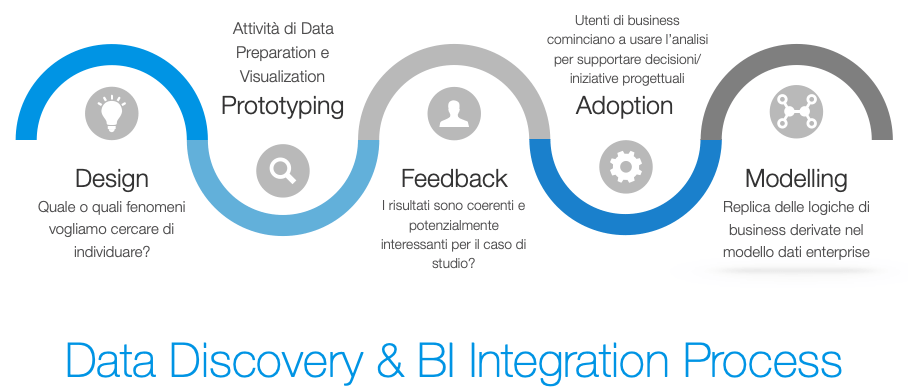
Il rapporto fra data discovery e data visualization
I processi di Data discovery si compongono di due fasi: la preparazione vera e propria; la visualizzazione dei dati.
La prima fase richiede competenze base, come conoscenze di modellazione per rendere i dati utilizzabili ai fini della visualizzazione e per garantire la correttezza delle informazioni esposte. In questa fase è possibile connettere dati aziendali strutturati con fonti di dati esterni come fogli Excel, feed provenienti da strumenti di Web Analytics (tool come Google Analytics), Open Data eccetera.
La seconda fase, invece, si concentra sulla visualizzazione. Data discovery e data visualization sono infine aree collegate fra loro. Basta pensare al Data journalism e al Data storytelling che impiegano teorie di visualizzazione dell’informazione per comunicare messaggi di natura differente (dal livello di rischio di contagio tra attività in pandemia al racconto di guerra in Ucraina e l’impatto sul patrimonio culturale).
Pulizia dei dati
Il data cleaning significa innanzitutto separare e quindi cancellare il rumore di fondo.
Dopo averli organizzati e processati, può emergere che i dati siano incompleti, lacunosi o ridondanti: potrebbero infatti contenere errori o duplicati. Per rendere i risultati dell’analisi coerenti e affidabili, bisogna mettere a punto iniziative di data cleansing, in grado di offrire un livello di data quality all’altezza della data preparation. La fase è fra le più lunghe in termini di tempo, a causa della varietà e volume di dati coinvolti nel processo di analisi.
Tuttavia, la pulizia dei dati, pur essendo time consuming, rende il dataset completo e con una qualità adeguata per le fasi successive d’elaborazione. Il gioco vale la candela e il tempo non è affatto perso.

Data transformation
La quarta fase della Data Preparation è la trasformazione dei dati, per rendere i dati disponibili alla fruizione e dotati d’interoperabilità, compatibili con le applicazioni che vi accedono per le proprie finalità.
Un esempio è il formato della data: negli USA è MM/DD/YY (mese – giorno o -anno), mentre lo standard è il YY/MM/DD (anno – mese – giorno). Se non si trasformasse questo dato, risulterebbe un’incoerenza nei report. Offrire un unico formato della data rende invece i dataset coerenti al loro interno.

Data structuring
Bisogna modellare, strutturare e organizzare i dati in formati e sistemi compatibili con le richieste dei tool di analytics a disposizione dei data scientist.

Data enrichment
Il data enrichment è una competenza specialistica in possesso del data analyst. Arricchire di ulteriori informazioni i dati che emergono dal data structuring rappresenta il quinto step della data preparation. Il data analyst svolge questo compito, senza mai perdere di vista quelli che gli aspetti di utilità per il business.
Si tratta di un processo che richiede l’aggiunta di altre informazioni e la connessione con ulteriori fonti da cui provengono nuovi approfondimenti. L’ottimizzazione permette di alzare il valore informativo, rendendo i dati più profittevoli nelle fasi successive.

La validazione dei dati
La Data validation è l’ultimo atto della preparazione dei dati. Dopo aver passato gli step precedenti, i dati sono finalmente pronti per la loro validazione e pubblicazione, dopo averne verificato accuratezza e coerenza, attraverso operazioni automatizzate.
Ora i dati nei data warehouse, data lake e altre repository, possono essere analizzati ed elaborati per estrarne il valore.

Data publication
L’ultimo step è la pubblicazione dei data. La data publication permette ai dati di essere messi a sistema.
La pubblicazione consente la comunicazione verso gli stakeholder che hanno espresso interesse o hanno commissionato l’analisi dati in esame.
Il report delle informazioni può avvenire in diversi formati per rispondere ai requisiti iniziali. Per fare ciò, vengono spesso applicate differenti metodologie di data visualization in modo da indirizzare la comunicazione dei messaggi chiave contenuti nelle informazioni analizzate.
La visualizzazione dei dati rappresenta la costruzione delle analisi visuali che semplificano la fruizione di dati di interesse e supportano l’utente nel processo di decision-making. L’integrazione di funzioni statistiche (regressione, clustering eccetera) e suggerimenti automatizzati, per supportare l’individuazione di potenziali problematiche, hanno permesso l’evoluzione dei più popolari strumenti di data discovery.
Data Visualization e data storytelling, infine, sempre di più integrano opzioni di governance ed orchestrazione dei dati, per semplificare, contestualizzare e rendere comprensibili i dati. Infatti la data publication aiuta a rendere i dati visibili ai decision maker. Così possano trasformare le informazioni in azioni e generare valore mediante decisioni coerenti ed efficaci.