
Un database agnostic è una banca dati in grado di memorizzare, elaborare, modificare e interconnettere data agnostic senza dover dipendere da uno specifico database management system (DBMS). Anche una tecnologia può essere database agnostic, per realizzare applicazioni compatibile con molteplici database.
Agnostico deriva dal greco e significa “non conoscibile”, il termine si trasla in ambito informatico. Ecco cosa significa, quali vantaggi e rischi comporta.

Cosa significa database agnostic
Il database agnostic si riferisce a un database che usa data agnostic ovvero quando il metodo o il format della trasmissione dati è indipendente dalla funzione dei programmi. Significa che il database riceve dati in molteplici formati o da molteplici sorgenti, processando quei dati in maniera efficace.
I database agnostic si riferiscono anche alla capacità di un software di funzionare con qualsiasi DBMS di qualsiasi vendor. Il Dbms è il software che consente la realizzazione, gestione e interrogazione del set di dati organizzati, secondo principi, nei database.
Nell’IT, “agnostico” riguarda per esempio un software o hardware che funziona con vari sistemi operativi, invece di declinarsi a un singolo sistema.
Un software database agnostic può risultare utile in un ambiente dove la sorgente dei dati deriva da database eterogenei. Inoltre un database agnostic non è progettato per lavorare con uno specifico DBMS, dunque non può trarre beneficio delle speciali funzionalità che tali sistemi offrono.
Il database-agnosticism è spesso offerto come funzionalità della business intelligence (BI), business analytics e di soluzioni enterprise resource planning (ERP).
Infine un database può essere cloud-nativo e cloud-agnostico. In questo ultimo caso non importa se l’applicazione è creata sul cloud con risorse software virtuali.

Gli schema-agnostic database
Gli schema-agnostic database sono anche detti vocabulary-independent database, in quanto supportano gli utenti a essere indipendenti dal vocabolario e supportano il matching semantico automatico fra query e database. Lo schema-agnosticism rappresenta la proprietà di un database di mappare una query, emessa con la terminologia e la struttura dell’utente, mappandola in automatico al vocabolario del dataset.
Esempi di database agnostic
Un esempio è un sistema di eCommerce, sviluppatore in linguaggio Java e JavaScript. Ovviamente, dovrebbe avere un database per immagazzinare prodotti, ordini, transazioni eccetera.
Ma lo shopping online utilizza qualsiasi database engine per quello scopo. Dove per qualsiasi database engine si intende un’ampia scelta: SQL Server, Oracle, MySQL, PostgreSQL, NoSQL, relazionali.
Ma non c’è solo l’eCommerce, altro campo di utilizzo è quello dei trade order nei servizi finanziari.

Implementazioni
Quando si archiviano i dati in un formato di storage generico, questa sorgente funge da entità di layer di sincronizzazione. Il formato di storage generico può interfacciarsi con una varietà di differenti programmi, con un metodo di estrazione di dati che formatti i dati in modo tale che un programma specifico può capire. Ciò permette ai programmi che richiedono data format differenti di accedere agli stessi dati. Molteplici database agnostic possono creare, leggere, leggere e cancellare (CRUD) le stesse informazioni dalle medesime storage location senza fare errori.
Poiché il synchronization layer è un’entità data agnostic, l’aggiunta di altri può costringere al recoding dell’intero database agnostic. I concept creati in altri programmi (che non contengono quel campo) vanno bene.
I database agnostic agevolano il trasferimento dei dati, senza richiederne la conversione. Memorizzare i dati in un synchronization layer funge da compatibility layer, da cui recuperare, aggiornare, ordinare e scrivere dati, a prescindere dal format impiegati.
Nel mondo Java, si usa la tecnica ORM (Object Relational Mapping), per operare con objects in Java e permettere alle library (come Hibernate) di trattare con le differenze dei database engine. In pratica, in Java la mappatura degli objects alle tavole in un database, permette objects. La library consente di costruire SQL query per uno database engine specifico.
Infine è possibile realizzare database-agnostic application usando Entity Framework di Microsoft.

Benefici
Se i dati del database agnostic sono trattati come agnostici, la programmazione è semplificata, dal momento che deve trattare solo con il caso dei data agnostic e non con molteplici casi. Ciò riduce il numero dei casi individuali.
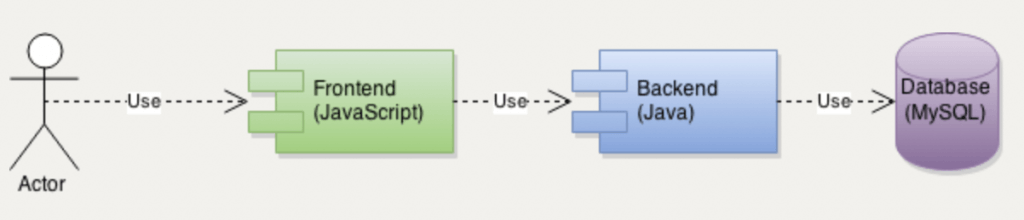
Il front-end può essere sviluppato in JavaScript, eseguito da un browser su un computer di un utente con un certo sistema operativo. Invia richieste al backend scritto in Java, eseguito su un server. Il backend in Java non rende persistenti i dati, dunque interroga un database MySQL per fare ciò. Il database in MySQL risponde con dati che il backend in Java processa e invia al frontend in JavaScript. Il client browser presenta una pagina web con i dati.
Se un’azienda usa MySQL come database engine, un’altra utilizza Oracle per supportare il traffico crescente ed un’altra Microsoft SQL Server, il vendor utilizza un’applicazione per database agnostic indipendente dal database engine.
Un problema deriva dal fatto che alcuni SQL datatypes non sono condivisi da tutti i vendor di database: i BOOLEAN non esistono in Oracle. Il database agnostic risolve questa problematica.
Rischi
Il database agnostic introduce alcuni problemi. Se solo un pezzo di codice è usato per operazioni CRUD (indipendenti dal concept), c’è un singolo punto di fallimento. Se quel codice presenta debolezze, l’intero sistema presenta vulnerabilità. Per mitigare questo rischio, è sufficiente testare innumerevoli volte il codice.
Inoltre, i database che usano data agnostic sono in grado di aumentare la velocità di caricamento, dal momento che il codice deve cercare le definizioni di campo e visualizzare il format così come i dati specifici da visualizzare.
La velocità di caricamento può essere migliorata, usando una copia dei record con i dati già estratti per indicizzare i campi, invece di dover estrarre i campi e formattare le informazioni nello stesso tempo dei dati. Poiché ciò genera un incremento della velocità, aggiunge un elemento di non-data agnostic al processo. Può essere facilmente creato attraverso una generazione di codice.
Infine, un rischio può derivare dalla difficoltà di scrivere software indipendenti dal database engine.



















