Il data sampling è un metodo di rilevazione statistica, destinato all’analisi dei dati, per ottenere dati di un campione rappresentativo.
Nella data analysis, il data sampling rappresenta la pratica di analizzare un sottoinsieme di tutti i dati, al fine di scoprire informazioni significative in un più ampio data set. Ecco cos’è il data sampling, quali sono le soglie di campionamento e le applicazioni.

Cos’è il data sampling
Il data sampling è una tecnica di analisi statistica, impiegata per selezionare, manipolare ed analizzare un sottoinsieme rappresentativo di data point, al fine di identificare pattern e tendenze nel data set sotto esame.
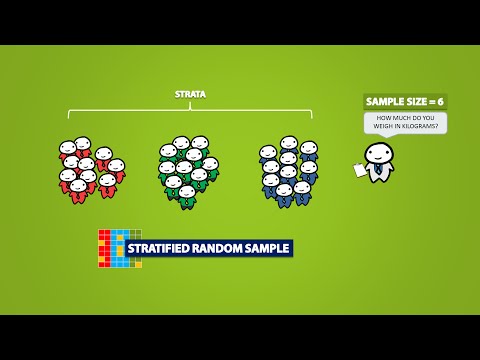
Il sampling si riferisce a un gruppo dedicato alla raccolta dei dati. Per esempio, se si cercano le opinioni di studenti in una università, sarebbe necessario fare un sondaggio su un campione di 100 studenti. In statistica, il sampling permette di testare un’ipotesi sulle caratteristiche di una popolazione.
Sono tecniche impiegate per prevedere il comportamento dei clienti, tendenze di mercato ed altri eventi in ambito business.
Soglie di campionamento
I rapporti predefiniti non sono soggetti al data sampling. Query ad hoc dei dati, ovvero le interrogazioni per ottenere informazioni sul contenuto di una base di dati, sono invece soggette alle soglie di campionamento.
Per esempio, Google Analytics elenca così le soglie di campionamento:
- Analytics Standard: 500 mila sessioni al livello property dell’intervallo di date che si sta utilizzando;
- Analytics 360: 100 milioni di sessioni al livello di visualizzazione, per l’intervallo di date in uso: le query possono includere eventi, variabili personalizzate e dimensioni e metriche customizzate. Tutte le altre query hanno una soglia di campionamento di un milione; dati storici, limitati fino a 14 mesi (in via continuativa).
In alcune circostanze, è possibile vedere meno sessioni campionate. Ciò dipende dalla complessità delle implementazioni dell’Analytics, dall’utilizzo di filtri di visualizzazione, dalla complessità delle query per la segmentazione, o dalla combinazione di tutti questi fattori. Nonostante sforzi e impegno a determinare le soglie di campionamento, è normale vedere talvolta minori sessioni di visualizzazione restituite per una query ad hoc.

Quando è applicato il data sampling
L’Analytics ha un set di rapporti predefiniti e preconfigurati, elencati sotto le categorie di Audience, Acquisition, Behavior e Conversions. Archivia un set di dati, completo e non filtrato, per ogni property in ciascun account.
Per esempio: per stimare il numero di alberi in un campo da 100 acri, dove la distribuzione degli alberi risulta abbastanza uniforme, sarebbe possibile contare il numero degli alberi in 1 acro e moltiplicare per 100. Oppure si contano gli alberi in metà acro e si moltiplicano per 200, per ottenere una rappresentazione accurata di 100 acri.

Default report
L’Analytics crea tavole di dimensioni aggregate e metriche derivanti da dati completi e non filtrati. In caso di default report, l’Analytics interroga le tavole dei dati aggregati per offrire velocemente risultati non campionati.
I default report non sono campionati sia in Analytics Standard che Analytics 360. Comunque, è possibile fare esperienza di data sampling in alcuni report di Google Ads.
Ad hoc report
Se si modificano default report, per esempio applicando segmenti, filtri o dimensioni secondarie o se si crea un custom report, combinando dimensioni metriche assenti in un default report, è possibile generare una query ad hoc di data Analytics.
L’Analytics prima verifica se nelle tavole dei dati aggregati sono disponibili richieste di informazione dalle query ad hoc. Se le informazioni non risultano disponibili, l’Analytics interroga il set di dati completo e non filtrato, per soddisfare la richiesta di query.
Le query ad hoc sono soggette a data sampling, se il numero di sessioni per il date range in uso superano le soglie per il property type.
L’algoritmo di data sampling usa un campionamento completo dei dati proporzionale alla distribuzione giornaliera di sessioni per la property per l’intervallo di date in uso.
La frequenza di campionamento varia da query a query. E dipende dal numero di sessioni durante l’intervallo di date per una data visualizzazione.
Durante un data sampling, i cima al report un messaggio indica che il report si basa su una percentuale di sessioni.
Nella parte destra del messaggio, è possibile selezionare una delle due opzioni per cambiare le dimensioni del data sampling: migliore precisione, quando usa la dimensione massima del sample per fornire i risultati più precisi per rappresentare il data set; risposte più veloci, con dimensioni del sampling più piccole, per accelerare le risposte.
Work sampling
Il work sampling può essere utile per effettuare il monitoraggio di attività di un determinato gruppo di persone nell’ambito di alcuni campi professionali.
In una realtà aziendale, consente di svolgere l’analisi del lavoro produttivo e non. Calcola le perdite e monitora il lavoro di ufficio.