
Quando si parla di big data e analisi, si affronta un discorso per principio molto ampio. In questo articolo ci concentriamo sui data integration tool, prendendo spunto dal report “Gartner Critical Capabilities Report for data integration tools“, complementare al ben più noto Gartner Magic Quadrant, diventato ormai letteratura di riferimento per chi si occupa di dati.
Il rapporto che esaminiamo parte dall’assunto secondo il quale, entro il 2024, le attività di integrazione ancora svolte manualmente verranno ridotte del 50% grazie all’adozione di modelli di progettazione di data fabric. Prima di addentrarci nell’argomento, è doveroso chiarire il concetto stesso di data fabric.
Data fabric, cos’è
Un data fabric è un ambiente che accorpa servizi e tecnologie al fine di massimizzare il valore dei dati, rendendo così più facile la loro gestione.
Un ambiente che attinge a dati di diversa origine e provenienti da diverse fonti ed è in grado di elaborarli al proprio interno. Allo stesso modo, applicazioni esterne, possono accedere al data fabric sia per fare uso delle informazioni, sia per procedere all’analisi delle stesse. Ciò permette un’analisi avanzata e più accurata dei dati, così come rende più facile l’applicazione delle norme a tutela dei dati stessi e la loro distribuzione agli stakeholder, anche sotto forma di app create espressamente.
Se, a una prima lettura, un data fabric può richiamare in qualche modo l’ormai datato concetto di data warehousing o di database relazionale, occorre specificare che l’architettura del data fabric è più articolata e complessa, tant’è che dipende dallo scopo ultimo che può essere: l’uso in favore di analisti dei dati, di ingegneri o del mero uso esecutivo delle informazioni. Inoltre, e qui si arriva al vero nocciolo della questione, un data fabric permette l’integrazione, l’uso e la condivisione di dati verificati in un ambiente distribuito.
Citare gli elementi essenziali di un data fabric è compito arduo, proprio perché variano a seconda dell’uso principale che se ne vuole fare. A prescindere da ciò, alcuni requisiti sono inalienabili. Tra questi:
- possibilità di gestione e integrazione di dati almeno da due sorgenti e applicazioni diverse
- possibilità di collegarsi a sorgenti dati senza necessità di scrivere codice (connettori pre-packaged)
- gestione di ambienti multipli (on premise, cloud e ibridi)
- preparazione e la governance dei dati mediante automazione per migliorare la qualità dei dati (tipicamente via machine learning)
- supporto di processi in real-time e batch e la condivisione dei dati mediante Api.
Data integration tool, il report di Gartner
Il rapporto prende in esame 21 vendor e ne valuta gli strumenti di integrazione dei dati (data integration tool) sulla scorta di 12 peculiarità e di 4 destinazioni d’uso, ossia:
- Data engineering
- Cloud data integration
- Operational data integration
- Data fabric
Prima di procedere, oltre alla definizione di massima del Data fabric, è bene fornire rapide descrizioni degli altri tre casi d’uso, a partire dall’ingegneria dei dati che consiste nella creazione e nella gestione di dati a supporto delle necessità di analisi. Nel caso specifico preso in esame dal report, non si fa riferimento alla disciplina vera e propria ma a una sua declinazione più contenuta.
L’integrazione nel cloud è intesa come migrazione di dati e di carichi di lavoro su ecosistemi che vanno da quelli locali (on premise) fino al multicloud.
Infine, l’integrazione dei dati operativi fa riferimento ad attività quali l’acquisizione e la condivisione di dati tra enti diversi (B2B), la data governance e la sincronizzazione tra processi aziendali.
Le finalità del report di Gartner
I concetti e le informazioni che abbiamo estrapolato dal report sui data integration tool si rivolgono a un pubblico orientato a valutare fornitori che offrono strumenti per l’integrazione dei dati e che necessitano di:
- Garantire il supporto DataOps anche dopo l’introduzione di nuovi metodi di distribuzione dei dati
- Elaborare dati provenienti da più fonti, anche davanti alla necessità di ottimizzarne la qualità
- Creare un’architettura Data fabric
Le valutazioni sono espresse da Gartner sulla scala che va da 1 (scarso) a 5 (supera i requisiti attesi). Il valore 3 rappresenta la piena sufficienza.
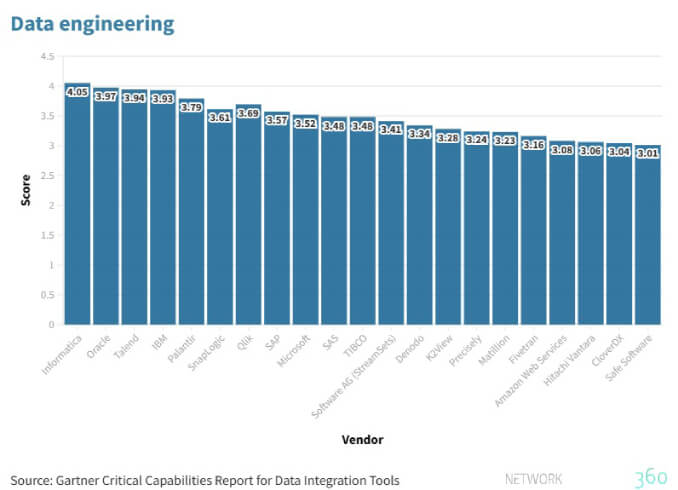
Quelle scelte da Gartner sono tutte soluzioni orientate al Data engineering con un accento su quelle offerte da Informatica, Oracle e Talend.
Alla soluzione di Informatica viene riconosciuta una spiccata vocazione alla trasformazione di dati complessi, peculiarità tipica anche di Oracle soprattutto negli ambiti del Machine learning e dell’intelligenza artificiale in genere, perché in grado di semplificare con poco codice la complessità dell’architettura dei dati. Al contrario, Oracle non si distingue nell’Operational data integration – come vedremo – a causa della necessità della condivisione dei metadata, cosa che riduce le possibilità di scambio di dati con prodotti non Oracle.
Dal punto di vista della preparazione dei dati, Talend offre un tool appositamente pensato (Talend data Preparation) per essere di facile utilizzo e che, sempre secondo le opinioni di Gartner, è tra i più apprezzati.
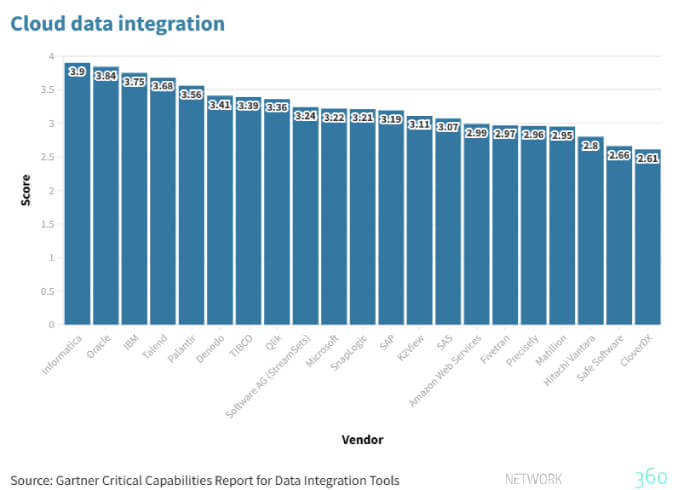
Si confermano ancora leader Informatica e Oracle. La prima si distingue grazie a due prodotti, chiamati Cloud data integration e Cloud Integration hub, capaci di lavorare in batch (e microbatch) per distribuire dati su diversi sistemi.
Oracle Golden Gate è invece la soluzione per la distribuzione di dati in tempo reale, anche in questo caso attraverso diversi sistemi.
Gartner non inventa, si limita a raccogliere informazioni e preferenze da chi fa uso delle diverse soluzioni. Appare tuttavia strano che IBM non abbia una valutazione più alta perché, con le remote runtime as a service, è possibile gestire la data integration con efficacia tanto su sistemi on premise quanto su sistemi multicloud, un vantaggio non indifferente per chi predilige le soluzioni ibride.
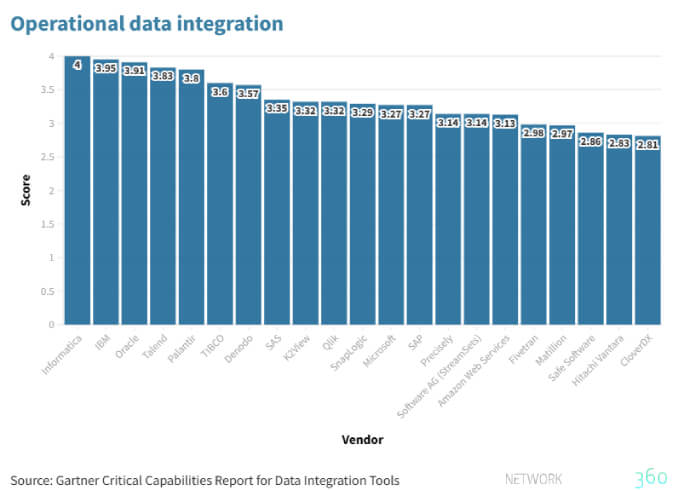
Informatica ha dalla sua una vasta gamma di data collector che permettono di interfacciarsi con diverse tecnologie e con diverse tipologie di dati grazie a procedure di polling continue e personalizzabili.
IBM offre, per contro, connettori orientati soprattutto ai database relazionali e Oracle, come scritto, mostra qualche limite laddove occorre uno scambio bidirezionale di metadata.
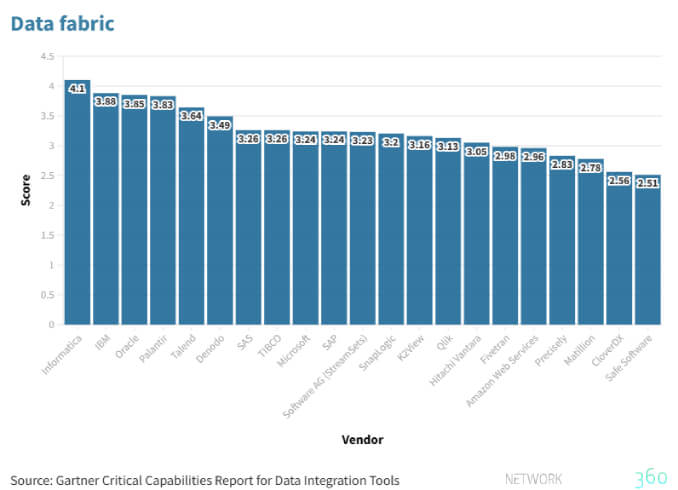
Il concetto di Data fabric, così come prevedibile, ricalca l’andamento delle analisi delle altre funzionalità, non stupisce quindi che le soluzioni più usate e apprezzate sono quelle di Informatica, IBM e Oracle le quali, per numero di tool a disposizione, permettono di coprire diverse necessità sia all’interno delle organizzazioni sia al loro esterno, con qualche limite nella condivisione dei dati che, a quanto stabilito da Gartner, possono essere aggirati.
Conclusioni
Gartner, esaminando le risposte fornite dal mercato, crea analisi e graduatorie imparziali e queste, nel panorama specifico degli strumenti per la data integration, premiano player rinomati come Oracle e IBM. Altri grandi nomi, tra questi Amazon Web Services e Microsoft, risultano non essere tra le preferenze degli utenti. Ciò non significa che non possano aggiudicarsi fette di rilievo del mercato, significa invece che nel segmento della raccolta, della conservazione, della gestione, della pulizia e della condivisione dei dati tendono a collaborare a vario titolo sistemi diversi.
Laddove non è possibile utilizzare le tecnologie di un unico vendor – e nel caso della condivisione di dati tra entità diverse appare poco probabile riuscire a farlo – occorre identificare quei sistemi i quali, grazie a tool forniti anche da terze parti, meglio si adeguano ai singoli contesti.

















