
Il deep analytics è l’applicazione di sofisticate tecniche di data processing per produrre informazione da ampi data set, di solito provenienti da molteplici sorgenti, contenenti non solo dati strutturati, ma anche non strutturati e semi-strutturati.
Per i data analyst l’esecuzione di dashboard è un dispendio di tempo, sottratto a questioni più importanti sui business critici. Questo è uno spreco di risorse sia per gli individui che per il business. Il deep analytics risponde a queste esigenze. Ecco cos’è e cosa significa per la business intelligence.

Indice degli argomenti
Cosa è il deep analytics
Il deep analytics è l’analisi in grado di trovare risposte a domande semplici, ma che richiedono un’esplorazione in profondità, organizzando e condividendo ciò che è stato scoperto.
Opposto allo shallow analytics, più focalizzato nel costruire metriche generiche e condividere insights via dashboard, permette al business di capire che cosa abbia contribuito a generare un’improvvisa crescita di un dato (fatturato eccetera), andando in maggiore profondità rispetto ai metodi tradizionali. E fa ciò, scomponendo la questione in molteplici, specifiche query.
Un esempio di deep analytics
Il deep analytics consente al business di capire che cosa abbia contribuito a generare un’improvvisa crescita nel fatturato, esaminando in maggiore profondità rispetto alle classiche dashboard dei ricavi e ai numeri del traffico. La scomposizione in query più mirate (query relativa al marketing, al prodotto e al fatturato) prevede il seguente processo: suddivisione del ricavato per ogni mese, nell’ultimo anno; ricerca dei pattern stagionali per il controllo incrociato mensile del fatturato, a intervalli di 12 mesi; i dati sul budget del marketing e sui dati di traffico; dati d’utilizzo, suddivisi in base alle differenti azioni degli utenti; ricerca delle differenti azioni intraprese da utenti e gruppi di essi.
In questo esempio, il deep analytics scopre che si è verificato un effetto stagionale: le persone comprano di più in certi periodi dell’anno. Inoltre un’efficace campagna marketing ha alimentato e spinto il traffico verso un prodotto, oppure un gruppo di utenti ha avuto un impatto materiale sui ricavi.
Cosa significa deep data
I deep data sono un sottoinsieme dei big data, con cui condividono alcune elementi affini. Sia i deep data che i big data condividono le stesse informazioni raccolte su basi giornaliere dal business, a livello globale.
Inoltre in entrambi i casi, l’analytics (sia deep che big data analytics) permette di aiutare le organizzazioni a prevedere le tendenze dell’industria e a sviluppare strategie operative efficienti.
Dunque è prioritario seguire i flussi di lavoro profondi. La business community non dà peso ai deep workflows, anche se si tratta di un lavoro che genera la maggior parte dei risultati aziendali. Gli insights non si materializzano fissando le dashboard, ma provengono dal business e dall’analisi dei dati in modi nuovi e non banali. E, per definizione, ciò non può essere svolto in modalità standard e uniforme.
Perfino la comunità dell’analytics non dà giusto peso ai deep workflows. La mancanza di cura ha come effetto una mancanza di standard e strumenti. Per esempio, SQL IDE non è stato ridisegnato per decenni. Occorre invece ripensare di condividere ed organizzare le analytical query. Non ci sono neanche standard nella scoperta e selezione di differenti versioni dei dati analitici da usare per i data analysis.
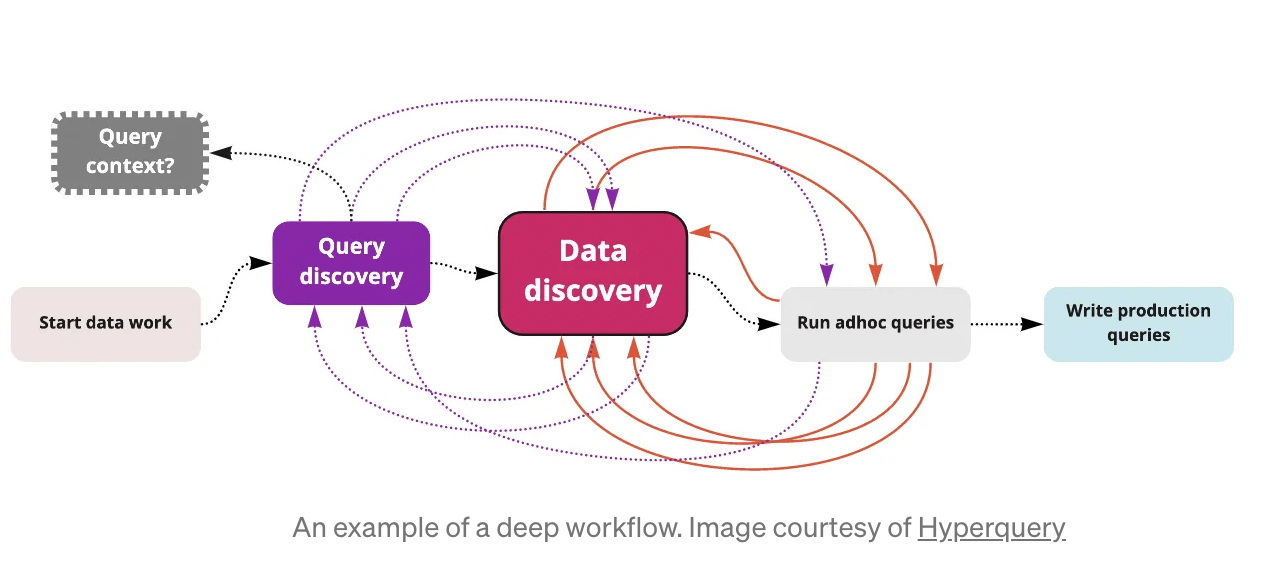
Deep analytics per la business intelligence
Gli strumenti non si limitano a rendere un flusso di lavoro più efficiente. Sono i tool a definire i workflow. Come Github lo ha fatto nel mondo del coding, Figma nel design delle interfacce, Ableton Live nella produzione di musica elettronica. Adesso è l’ora dei tool in grado di definire il deep analytics.
Gli strumenti tradizionali per la business intelligence (BI) non sono la risposta giusta. Sono costruiti per aiutare gli analyst a realizzare data tool self-service (come le dashboard) per un pubblico aziendale generico.
SQL IDE sono dedicati alle transazioni, non per esplorare, a causa delle troppe tabs). I notebook Jupyter sono ideali per i flussi di lavoro di data science in Python, ma non si adattano all’analytics.
I tool di Data Discovery sono perfetti per una generica osservabilità, ma non sono integrati nel flusso di lavoro di di query-writing. I wiki tool come Notion e Confluence sono luoghi di uso generale per condividere informazioni, ma non sono appositamente creati per condividere insights di analytics.
Abbiamo definito la data science come disciplina. Il deep learning è un apprendimento trasformativo di modelli predittivi. Abbiamo inventato il termine Business Intelligence per dare importanza ai processi decisionali data-driven attraverso strumenti self-service. Più recentemente, abbiamo inventato un’intera nuova professione: l’Analytics Engineer. Adesso è giunta l’ora di prestare attenzione alla categoria del deep analytics. Servono i tool per renderlo più efficiente e performante.















