
Nel 2019, nella mappa di Gartner “Hype Cycle for Analytics and Business Intelligence”, emergeva già un trend di particolare interesse nella governance dei dati, ovvero nel come governare i dati. Le aspettative su strumenti di Data Catalog sono in una fase discendente e ritenute comunque a uno stato di maturità non consono per la velocità con cui si muove lo sviluppo tecnologico.
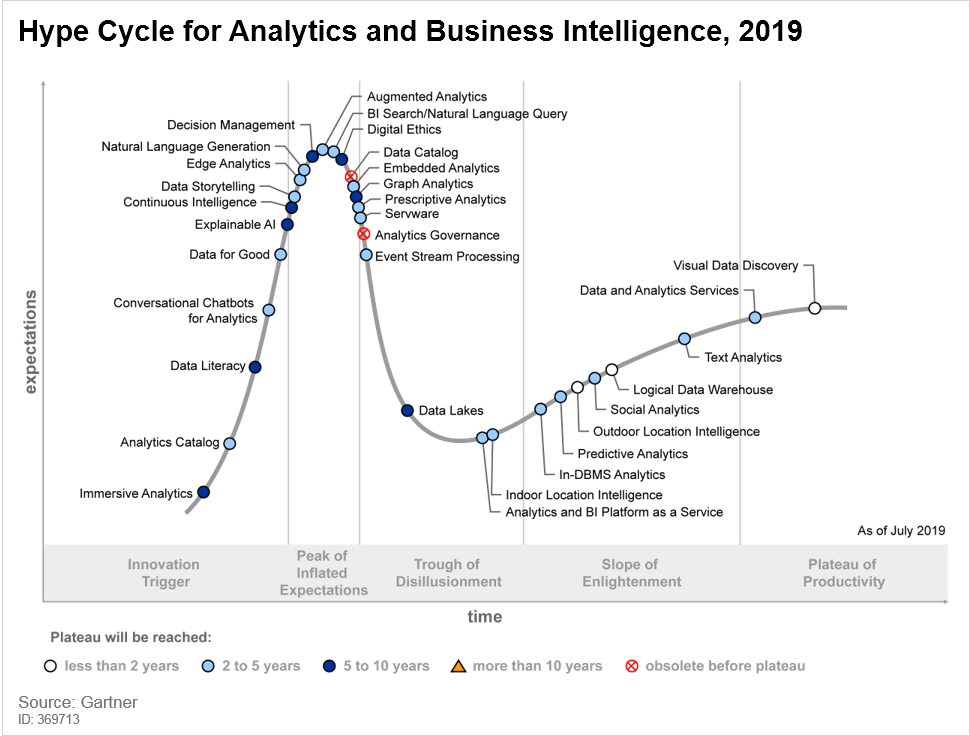
L’importanza di mappare le informazioni presenti in azienda, la gestione della loro completezza e qualità, non è di sicuro messa in discussione. Il detto “garbage in, garbage out” è oggi più che mai una verità che va gestita all’interno di contesti dove il data lake sta inglobando sempre più informazioni.
È per questo motivo che bisogna intervenire tempestivamente e superare attività manuali di mappatura delle informazioni che si portino dietro rischio operativi di gestione manuale o tempistiche inefficienti.
In quest’ottica gli algoritmi di machine learning possono aiutare notevolmente la gestione dell’informazione, la comprensione dell’utilizzo del dato e la comprensione del patrimonio informativo veramente di interesse su cui si basano le prese di decisioni aziendali.
Le aziende che hanno compreso l’importanza del dato e ne hanno fatto un asset strategico aziendale diventando vere e proprie data-driven company, devono oggi tenere in considerazione e monitorare alcuni principali aspetti:
- Come le diverse funzioni stanno usando il patrimonio informativo a disposizione?
- Esiste una omogeneità tra i numeri che i diversi stakeholder interni utilizzano per prendere decisioni?
- I report direzionali sono tutti coerenti in termini di perimetro di riferimento e logiche di business gestit?
- All’interno dei singoli gruppi di lavoro, come possiamo rendere agile la condivisione di un’informazione attraverso una data literacy sempre aggiornata?
FAIR: seguire un framework open di riferimento
In una pubblicazione del Marzo 2016, un gruppo di scienziati e ricercatori ha definito dei principi di base per la gestione dei dati scientifici.
In particolar modo, questi principi toccavano 4 principali leve: Findable, Accessible, Interoperable e Reusable.
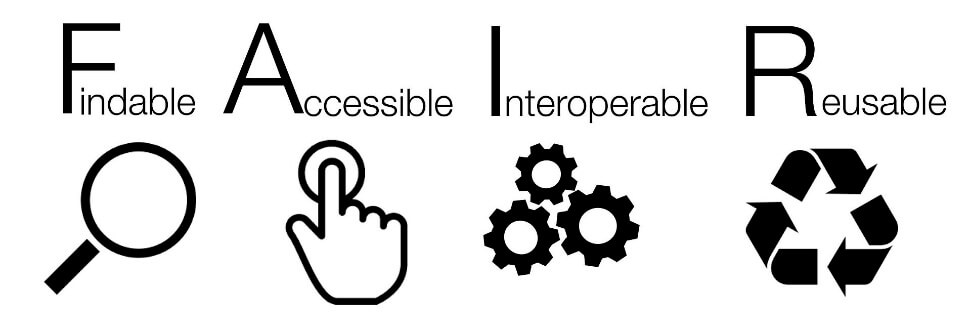
Tali principi enfatizzano la capacità delle macchine e degli algoritmi esperti di rendere fruibile l’informazione anche all’aumento del volume, della complessità e della velocità di produzione di nuove informazioni. In una comunità scientifica tali principi possono ritenersi la base di un approccio open alla collaborazione.
Tuttavia è difficile pensare che questi principi non debbano essere presenti in contesti di collaborazione aziendale o, pensando al mondo della Open Innovation, nell’ambito della co-innovazione tra realtà complementari che possono fare dello scambio dei dati un asset di valore bidirezionale.
Entriamo nel dettaglio:
- Findable – Individuabili: per poter utilizzare i dati è necessario trovarli. Sia metadati che dati dovrebbero essere censiti e individuabili facilmente da computer e persone. In particolar modo i metadati giocano un ruolo fondamentale per la scoperta automatica da parte della macchina e per l’attivazione di un processo human-digital.
- Accessible – Accessibili: i dati devono poi essere accessibili agli utenti interessati, conoscendone le modalità di accesso e garantendo allo stesso tempo un rispetto della privacy secondo protocolli di autenticazione e autorizzazione.
- Interoperable – Condivisibili: i dati devono poter essere letti e integrati da più stakeholder. La capacità di collegarli a diversi sistemi, abilitarli a più processi aziendali e archiviarli in maniera omogenea permette di fare efficienza.
- Reusable – Riutilizzabili: è l’obiettivo finale del framework di riferimento. Ottimizzare il riutilizzo del dato attraverso la gestione di corretta di metadati e sistemi di lettura intelligente dell’informazione.
Questi principi rappresentano un buono schema di partenza per abilitare una governance del dato di valore.
A partire da questi principi, nel 2019 la Global Indigenous Data Alliance (GIDA) ha pubblicato anche dei nuovi principi CARE, complementari al FAIR, e che introducono concetti Open rispetto ad autorità di controllo, etica, responsabilità e beneficio collettivo.
Governare i dati nell’era della data intelligence
A partire dai principi precedentemente descritti sono nati diversi progetti per la condivisione e la gestione dei dati. Tra questi uno di particolare interesse può essere considerato OPAL, una piattaforma che con componenti tecniche basate su algoritmi open, ha l’obiettivo di valorizzare i dati privati a favore del bene comune attraverso il rispetto della privacy e attraverso un approccio sostenibile.
Con un focus di applicazione di questi principi ai contesti aziendali, di seguito sono rappresentati i principali benefici che un approccio flessibile, aperto e di condivisione può portare alle aziende:
- Maggiore efficienza operativa in termini di:
- Minor tempo di speso nella data discovery
- Minor tempo di data training sui nuovi colleghi
- Aggiornamento continuo di dati e metadati
- Maggiore efficacia per le analisi sui dati:
- Suggerimento all’utente in termini di scelta dell’informazione più giusta all’analisi di interesse
- Rinforzo collaborazione tra colleghi delle singole funzioni aziendali
- Suggerimenti e tips rispetto all’area tematica di analisi
- Apprendimento automatico:
- I sistemi di intelligenza artificiale imparano nel tempo dall’analisi del dato classificando l’informazione in modalità automatica
- Data similarity basata su machine learning, ovvero la comprensione di quali contenuti informativi possono considerarsi simili, complementari o ridondanti
- Scalabilità di applicazione:
- Approccio insight first su tutte le entità di analisi di interesse
- Possibilità di integrare facilmente qualsiasi nuova fonte dato
Alcune delle funzionalità di maggiore interesse in strumenti di intelligenza artificiale possono essere:
- SIB (statistics insight box): moduli per la descrizione del contenuto delle tabelle censite e individuazione delle principali informazioni relative al contenuto informativo, come ad esempio primary e foreign key, tipologia di dati, dimensione della tabella, frequenza di aggiornamento.
- QAS (query analysis system): sistema di analisi delle query che analizza automaticamente i comportamenti di frequenza di utilizzo delle tabelle e delle informazioni presenti nei DB da parte degli utenti. Sfrutta algoritmi di machine learning per interpretare il parsing e l’analisi del contenuto delle query storicizzate nei diversi sistemi aziendali. Inoltre, sfrutta una classificazione di dominio e di sotto-insiemi semantici al fine di individuare le aree dati più utili agli utenti finali.
- DEE (data enrichment engine): motore per la generazione nel continuo di un patrimonio informativo arricchito che descriva e classifichi tabelle, colonne ed entità dati rispetto alle diverse caratteristiche, come ad esempio: valori di distribuzione, tipologia, dimensione, ulteriori metadati a disposizione, ecc.
- SIM (similarity index machine): motore di machine learning che abilita metriche di similarità delle colonne analizzate nei DB aziendali, al fine di individuare elementi simili e utilizzabili nei diversi contesti semantici. La macchina è un mix di integrazione di diverse tecniche statistiche e matematiche come ad esempio l’utilizzo di tecniche non supervisionate e di raccomandation engine (es. Netflix).
















