
NCC (Nearest Neighbor Classifier) è il più semplice dei classificatori. Il “classificatore più vicino” è un metodo eccellente per predire il comportamento di un utente in sistemi di AI, come ad esempio i sistemi che raccomandano cosa fare, comprare, leggere, ascoltare, vedere.
Quando gli viene dato un oggetto da classificare, il classificatore cerca l’oggetto preso dal training set più “vicino” e, trovatolo, classifica il nuovo oggetto con l’etichetta che appartiene a quella del vicino.
Un esempio semplice da realizzare e di facile comprensione è quello che segue.
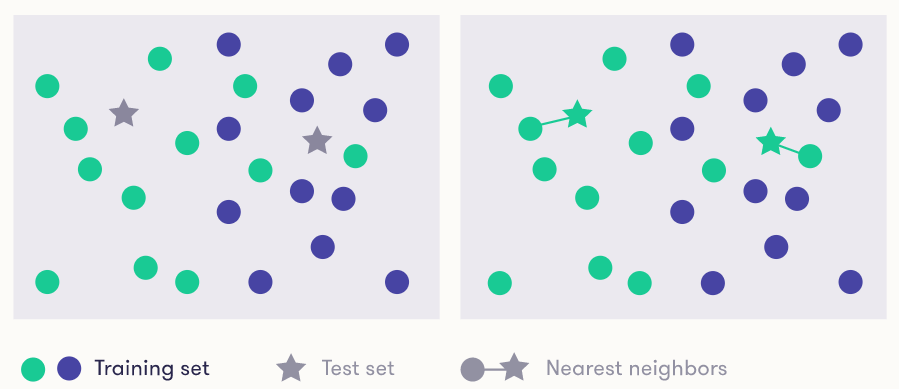
In uno spazio a due dimensioni, date X e Y come metriche in unità è abbastanza semplice calcolare il più vicino. Se si parla ad esempio di latitudine e longitudine, calcolare la distanza in chilometri è abbastanza semplice. Nel caso specifico inoltre le “label” sono solo due: verde o blu. Oppure immaginiamo che la X sia l’età e la Y il livello di glicemia: la signora Maria (la stella in alto a destra, che ha 50 anni e 107 di glicemia) e il signor Mario (che ha 82 anni e 105 di glicemia) sono a rischio diabete (verde)? Da quanto visto sopra sembra di si.
Ci sono due aspetti che complicano il problema: se il problema non è bidimensionale, ma multidimensionale e la definizione di “vicino”.
Nel primo caso, all’aumentare delle dimensioni, aumenta la complessità. Ma se le dimensioni sono tutte metriche, è facile calcolare la distanza. Diventa più difficile calcolare la distanza se le dimensioni non sono metriche (ad esempio sono un testo). Quindi il concetto di vicino va specializzato su ogni dataset.
L’idea alla base è molto semplice: utenti con un comportamento passato simile, avranno probabilmente un comportamento futuro simile.
Esempi pratici di utilizzo del classificatore NNC
Immaginiamo un sistema che raccomanda che musica ascoltare, che raccoglie i dati delle scelte degli utenti. Ipotizziamo di aver ascoltato musica dance anni ‘80 e ‘90. Un bel giorno, il fornitore di servizi musicali riesce a ottenere di poter aggiungere al catalogo un pezzo molto raro del genere dance anni ‘90. Il sistema deve quindi prevedere se consigliartelo oppure no. Il metodo “vecchio” sarebbe decidere in base ai metadata del brano (genere, artista, casa discografica …). Chiaramente questi metadata sono pochi e non aiutano molto a capire se il nuovo pezzo ti piacerà.
Quello che usano i sistemi di “raccomandazione/consiglio”, invece dei metadata sopra indicati, sono dei metodi di collaborative filtering. L’aspetto collaborativo deriva dal fatto che vengono usati i dati di altri utenti per prevedere il nostro comportamento. Il termine filtro deriva dal fatto che ci viene consigliato solo quanto passa attraverso un filtro di scelta: contenuti che probabilmente ti piacciono passano, contenuti che non ti piacciono non passano). Ecco perché si parla di filter bubble quando le proprie ricerche, dando appunto “risultati che ci piacciono” continuano ad alimentare le nostre credenze e idee.
Tornando alla musica anni ‘90, ipotizziamo che altri amanti della musica dance anni ‘80 e ‘90 abbiano ascoltato il nuovo brano e l’abbiano trovato eccezionale (ascoltandolo ripetutamente). È chiaro che il nuovo bravo passerà il cooperative filter e verrà presentato anche a noi, visto che ha funzionato con utenti che hanno preferenze simili alle nostre. Se invece in una realtà parallela lo stesso brano fosse stato poco gradito dai nostri “simili” musicali, allora non ci verrebbe proposto e sarebbe filtrato dal filtro collaborativo.
Un altro esempio tipico, è dato dai “consigli per gli acquisti” che capitano sui siti di acquisto online. Costruire un “sistema di raccomandazione di acquisti su un sito online” non è particolarmente complesso. Il sistema mano a mano che gli utenti comprano, memorizza le loro scelte, salvando dati (ecco perché si parla di big data, perché ogni nostra scelta è memorizzata e mantenuta per classificare il comportamento e creare cooperative filter).
Ipotizziamo di avere i dati di acquisto di 6 utenti:
| Utente | Storia degli acquisti (big data) | Ultimo acquisto | |||
Andrea | guanti da box | Moby Dick (libro) | cuffie | occhiali da sole | caffettiera |
| Luca | t-shirt | caffettiera | frigorifero | peluche | palla da rugby |
| Marco | occhiali da sole | sneakers | t-shirt | sneakers | palle da tennis |
| Alice | 2001: A Space Odyssey (dvd) | cuffie | t-shirt | guanti da box | smartwatch |
| Veronica | t-shirt | smartwatch | occhiali da sole | Moby Dick (libro) | cuffie |
| Anna | Moby Dick (libro) | caffettiera | 2001: A Space Odyssey (dvd) | cuffiette | caffettiera |
L’ultimo acquisto è quello sulla destra. Quindi l’ultimo acquisto di Luca, dopo aver comprato una t-shirt, una caffettiera, un frigorifero e un peluche, è stata una palla da rugby.
Per applicare il metodo del”più vicino” dobbiamo definire cosa è vicino, non avendo metriche numeriche. La più semplice metrica numerica rappresenta il numero di oggetti comprati nei primi 4 acquisti che sono uguali. Ad esempio la “vicinanza” di Veronica e Alice è: 1, perché nei primi 4 acquisti (escluso l’ultimo) hanno comprato solo la t-shirt in comune.
Il nostro obiettivo è immaginare cosa comprerà Tommaso:
| Utente | Storia degli acquisti (big data) | Ultimo acquisto | |||
| Tommaso | borracce | t-shirt | occhiali da sole | smartwatch | ? |
Tommaso è il nostro utente di test (test set) e gli utenti sopra (Anna, Alice, Luca, Andrea, Marco) il nostro dataset di training. Calcoliamo quindi le vicinanze di Tommaso agli altri.
Andrea 1 Luca 1 Marco 2 Alice 1 Veronica 3 Anna 0
Questo vuol dire che, probabilmente, Tommaso come prossimo acquisto comprerà delle cuffie, quindi vale la pena di presentargli qualche cuffia nei consigli per gli acquisti e nelle pubblicità associate al sito.
Immaginate se il training set fosse dinamico (continui acquisti e utenti che appaiono e scompaiono, ovvero big data in continua evoluzione) come migliorerebbe la probabilità di intercettare comportamenti equivalenti a quelli di Tommaso e scrivergli “utenti che hanno comprato X hanno anche comprato Y!”

















