Apache Cassandra è un DBMS, un sistema di gestione di database Open source NoSQL e, come tale, predisposto per i Big data.
La sua architettura scalabile ne consente la distribuzione su diversi server, non è quindi vincolato alla canonica infrastruttura di tipo master e ciò, oltre a rendere Cassandra più efficiente, ne fa un sistema affidabile.
È utilizzato da grandi imprese ed è stato sviluppato nel 2008 per rispondere alle esigenze di Facebook, piattaforma per eccellenza confrontata con grandi moli di dati e, negli anni a seguire, è stato adottato da altri giganti quali, per esempio, X (Twitter) e Netflix.
Apache Cassandra: panoramica del potente database NoSQL
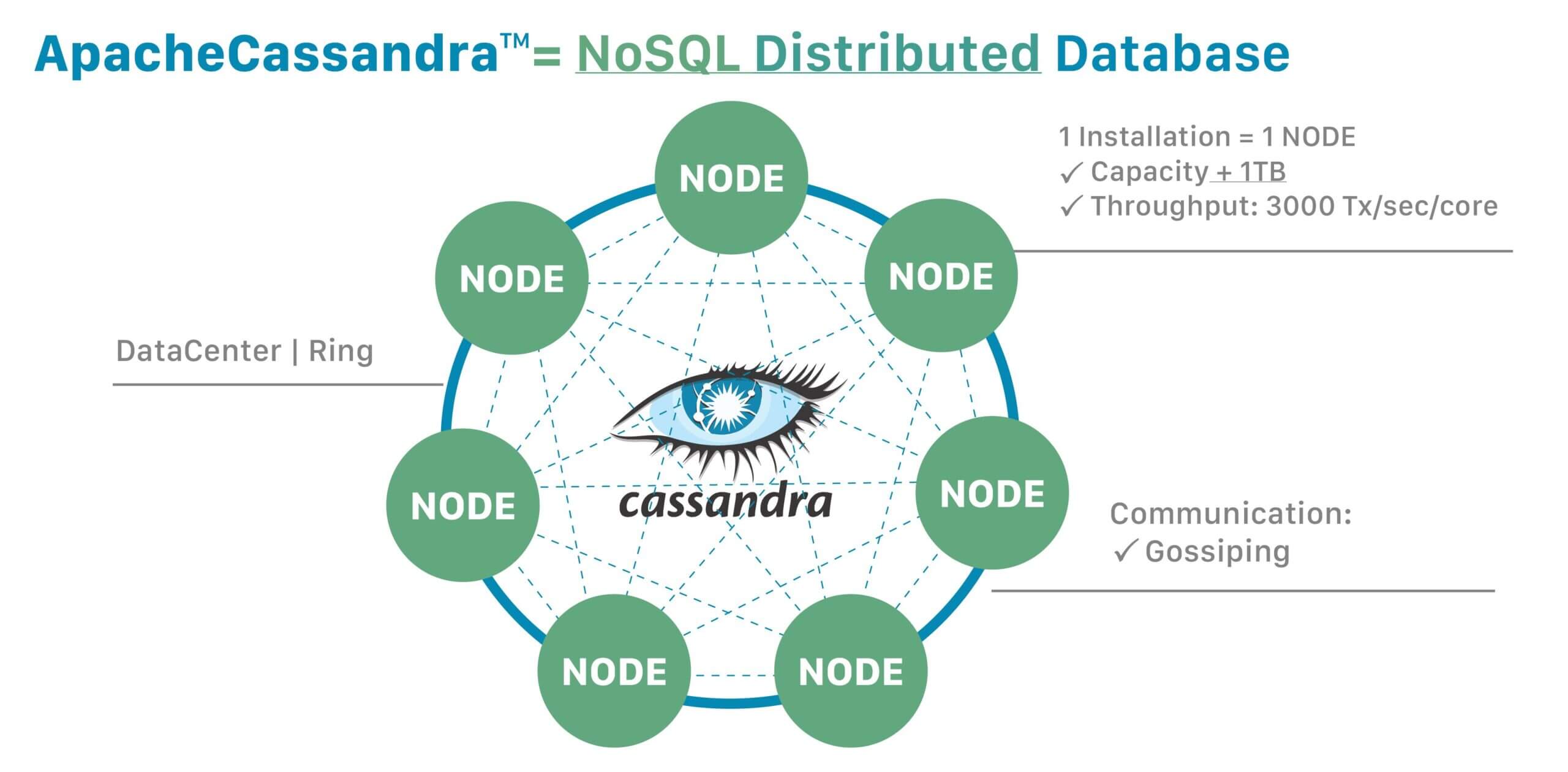
Con il termine NoSQL si fa riferimento a database che non sottostanno alle limitazioni del linguaggio SQL (Structured Query Language) e che offrono vantaggi di rilievo nell’elaborazione dei Big data. Cassandra, che dal 2009 è entrato a fare parte dei prodotti sviluppati da Apache Software Foundation, si distingue per scalabilità, affidabilità e disponibilità soprattutto perché consente di aggirare il single point of failure, puntando sulla distribuzione in cluster, ossia su diversi nodi (server) che si fanno carico di svolgere il lavoro. Il malfunzionamento di un nodo non inficia (o incide in modo limitato) sull’operatività nel suo insieme.
In termini più tecnici, usando concetti dei modelli cluster Dynamo, ossia usando un’architettura peer-to-peer (e non quella master/slave tipiche dei database relazionali) Cassandra garantisce il funzionamento anche in situazioni particolarmente critiche.
Caratteristiche distintive del DB open source Apache Cassandra
Tra le peculiarità citate sopra, l’utilizzo da parte di Apache Cassandra di concetti del modello di clustering DynamoDB merita un approfondimento preliminare: si ispira a Dynamo. Sì, Apache Cassandra utilizza alcuni concetti del modello di clustering DynamoDB³. In particolare, Cassandra si basa sullo stile Dynamo per quanto riguarda:
- il partizionamento dei set di dati tra i nodi del cluster
- l’associazione di chiavi primarie alle tabelle per l’identificazione univoca di righe ed elementi
Il fatto che Cassandra e DynamoDB abbiano architetture a tratti sovrapponibili non li rende la medesima cosa, tant’è che tra le due tecnologie vi sono differenze di rilievo.
Di fatto, nello specifico Cassandra si distingue per:
- la facilità nella distribuzione dei dati: consente di distribuire i dati replicandoli su più data center
- la flessibilità nell’archiviazione dei dati: Cassandra lavora con dati strutturati, semi-strutturati e non strutturati
- la flessibilità e la scalabilità: l’aggiunta e la rimozione di hardware per adeguarsi ai carichi di lavoro è una delle prerogative di Cassandra
- velocità di scrittura: Cassandra è progettato per scritture veloci a prescindere dall’hardware. Offre prestazioni di rilievo anche su sistemi non recentissimi.
Non da ultimo, e come già scritto in precedenza, l’architettura di Cassandra elimina i single point of failure e ciò è una garanzia per le applicazioni, anche per quelle business critical.
Architettura scalabile: come Apache Cassandra gestisce i Big data
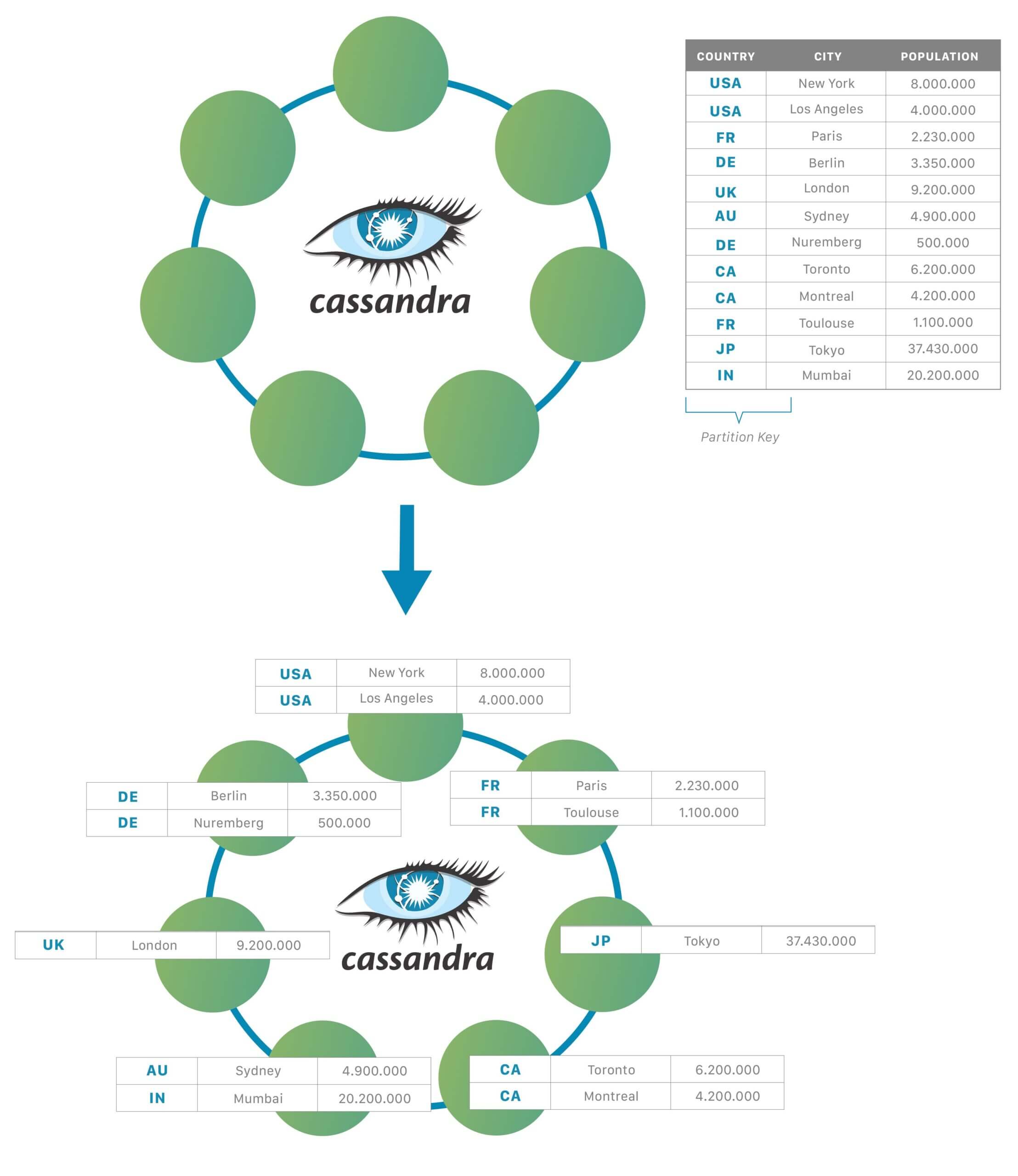
I dati non sono archiviati in un unico database residente su un server ma su diversi database e su server diversi. Inoltre, i dati possono essere replicati su più nodi del cluster ed essere quindi eseguiti su più server.
I dati sono organizzati in file chiamati “partition” (data partitioning) che vengono distribuite tra i nodi del cluster e ciò significa che, tendenzialmente, parte dei dati può essere archiviata su più server e persino in Data center diversi attraverso più aree geografiche.
Quindi, l’architettura distribuita e la scalabilità, Apache Cassandra è in grado di gestire grandi quantità di dati ma, a ciò, si accosta il linguaggio Cassandra query Language (CQL) il quale – non del tutto dissimile a SQL – è preferito dagli sviluppatori confrontati con i Big data.
Ruolo della scalabilità in Cassandra come database NoSQL
Quando si parla di Big data la scalabilità è argomento di rilievo. Apache Cassandra la interpreta secondo alcuni principi:
- scalabilità orizzontale: fa riferimento all’aumento di nodi di un cluster al fine di gestire i dati distribuendoli su più server senza interrompere i servizi che questi erogano
- disponibilità: le repliche dei dati su più nodi consente l’accessibilità ai dati stessi anche se un server fosse guasto o non più raggiungibile.
Tutto ciò si traduce nella capacità di Cassandra di offrire prestazioni costanti che sono capitali nella gestione dei Big data (e nell’erogazione di applicazioni web).
I database relazionali consentono invece una scalabilità di tipo verticale, incentrata soprattutto sul potenziamento dei server.
Affidabilità nel DB NoSQL di Apache Cassandra
Per quanto possa apparire ripetitivo, l’affidabilità di Cassandra ha origine nella propria architettura. Ancora una volta, anche in materia di affidabilità, emergono preponderanti la distribuzione peer-to-peer che elimina i singoli punti di errore e la replica dei dati che consente di bypassare nodi del cluster non funzionanti e senza subire interruzioni.
Elementi sufficienti a decretare il successo di Apache Cassandra nella gestione dei Big data.
Progettazione efficace dei dati in Apache Cassandra
Per potere sfruttare gli atout di Cassandra la progettazione dei dati è fondamentale e le pratiche che la consentono sono del tutto diverse da quelle dei database di tipo SQL.
- scelta delle chiavi di partizione: la chiave di partizione dei dati è il parametro che determina la distribuzione dei dati tra i nodi del cluster
- la modellazione: lo schema dovrebbe essere progettato a seconda della necessità di lettura dei dati, ovvero in linea con i modelli di accesso ai dati da parte delle applicazioni che ne fanno uso. La letteratura specifica parla di progettazione del modello dei dati in base alle necessità di query
- la pianificazione: le repliche dei dati vanno pianificati in base ai requisiti di disponibilità e al ciclo di vita dei dati stessi. Non tutti i dati hanno la medesima durata, alcuni possono essere gestiti ed elaborati per periodi più lunghi di altri
- la denormalizzazione: pratica consigliata per migliorare le prestazioni delle query (questo aspetto verrà approfondito subito sotto)
- la dimensione delle righe: se troppo grandi possono rallentare le prestazioni dei database.
Poiché Apache Cassandra non prevede operazioni di join tra tabelle (cosa tipica dei database relazionali), la denormalizzazione dei dati consente il miglioramento delle prestazioni di un database unendo e raggruppando le copie dei dati ridondanti.
Facilitare la migrazione al database NoSQL di Apache Cassandra
La migrazione ad Apache Cassandra può essere delicata e particolarmente impegnativa, soprattutto perché può imporre – soprattutto per chi fa uso di database relazionali – una visione completamente nuova dell’organizzazione dei dati che, come detto sopra, esigono uno schema progettato in base a come i dati saranno letti. Il modello di dati usati da Apache Cassandra è basato su colonne e quindi occorre tenerne conto durante la progettazione dello schema del database.
È in ogni caso probabile che le applicazioni sviluppate per lavorare con i database relazionali debbano essere riadattate
Prima di procedere con la migrazione è importante pianificare la distribuzione dei dati, decidendo quanti nodi formeranno il cluster Cassandra.
Soltanto dopo i dati potranno essere trasferiti a Cassandra. Apache offre strumenti che coadiuvano la migrazione e, non di meno, diversi provider propongono servizi simili e a prezzi variabili.
Passaggi chiave per una migrazione di successo a Cassandra
I passaggi chiave principali, come scritto sopra, possono essere ridotti a:
- adattare il modello dei dati
- adattare le applicazioni
- pianificare la distribuzione dei dati
- spostare i dati.
Nell’ordine, occorre comprende il modello di dati di Cassandra e progettare uno schema di database a seconda del modo in cui le query vengono eseguite, al fine di ottimizzare le prestazioni del database stesso.
Occorre poi tenere conto della scalabilità orizzontale di Cassandra, quindi della distribuzione dei dati tra i vari nodi del cluster, pianificando anche le politiche di replica dei dati stessi.
La migrazione vera e propria, che può avvenire soltanto dopo avere adempiuto alle necessità dei primi tre passaggi, può essere coadiuvata da strumenti appositi.
Rafforzare la sicurezza nel database NoSQL Apache Cassandra
In materia di sicurezza, le procedure raccomandate sono quelle comuni a qualsiasi altra tecnologia, tenendo però conto del fatto che Cassandra integra delle funzionalità di autenticazione e autorizzazione che vanno opportunamente configurate.
Il traffico dei dati va crittografato, così come vanno crittografati le informazioni a riposo nei database e ciò, insieme alla corretta implementazione e gestione delle politiche di accesso ai dati e al monitoraggio costante degli accessi e delle attività svolte da utenti e applicazioni, conferisce un buon substrato di sicurezza che, tuttavia, non può essere ritenuto sufficiente per scongiurare minacce.
L’aggiornamento regolare dei sistemi e dei software di sicurezza è ovviamente opportuno ma, a rendere veramente efficaci gli accorgimenti presi, gioca un ruolo fondamentale la cultura della cybersecurity che vige nelle imprese a ogni livello, dal management fino ai dipendenti e ai collaboratori.
















