In una società fortemente basata su sistemi informativi in grado di immagazzinare senza soluzione di continuità illimitate quantità di dati derivanti da fonti eterogenee, un valore aggiunto di fondamentale importanza per le organizzazioni pubbliche e private di tutto il mondo è rappresentato dalla capacità di acquisire nuova conoscenza, anche al fine di adottare decisioni strategiche e orientare i propri obiettivi di lungo termine, partendo da informazioni apparentemente non correlate o addirittura riferite a contesti totalmente divergenti. È questo, in estrema sintesi, l’ambito di riferimento del cosiddetto data mining, ossia di quell’insieme di tecniche e metodologie che hanno per oggetto l’estrazione di informazioni da grandi insiemi di dati, attraverso metodi per quanto possibile automatizzati.
L’obiettivo di fondo è quello di individuare, in maniera sistematica, organica ed efficiente associazioni, anomalie e schemi ricorrenti, conosciuti in ambito tecnico come “pattern”, all’interno di sterminate e sempre crescenti banche dati, con il fine principale di apportare vantaggi agli individui, alle imprese e alla collettività.
Si tratta di attività di fondamentale importanza, che hanno condotto a conquiste straordinarie per l’umanità quali l’intelligenza artificiale, in cui computer ed elaboratori elettronici riescono ad aggregare in tempo reale miriadi di dati per simulare le capacità cognitive del cervello umano, l’Internet delle cose, che permette ad esseri viventi, oggetti e dispositivi elettronici di scambiarsi informazioni, oppure a tutti quei sistemi, quali ad esempio le recentissime automobili a guida autonoma, in grado di processare miliardi di dati a una velocità impressionante.
Cos’è il data mining
Il data mining, partendo da informazioni disseminate senza un ordine prefissato in disparati archivi digitali dislocati virtualmente in ogni parte del mondo, punta a far emergere significati, legami, inferenze, connessioni e nessi di causalità che possano essere utilizzati per scopi scientifici, economici, finanziari, politici, ambientali e praticamente in ogni ambito della conoscenza umana.
Al fine di ottenere un quadro quanto più completo ed esaustivo, è necessario premettere che il data mining è generalmente incastonato all’interno di un processo ancora più complesso e articolato conosciuto come “Knowledge Discovery in Databases” (da cui deriva l’ormai celebre acronimo di KDD), il cui fine ultimo è quello di scoprire in maniera automatica modelli, regole e altri contenuti implicitamente presenti in grandi volumi di dati, attraverso una serie di step riassumibili, in estrema sintesi, nei seguenti passaggi operativi:
- Identificazione degli obiettivi e della tipologia di conoscenza da estrarre: rappresenta il punto di partenza che orienta in maniera decisiva tutti i successivi passaggi. Si pensi, ad esempio, alla necessità di acquisire nuove quote di mercato, di scoprire le correlazioni tra i gusti dei consumatori ed i loro acquisti oppure, passando ad un campo maggiormente scientifico, alla ricerca di fattori scatenanti di malattie o, al contrario, di elementi in grado di prevenirle.
- Preselezione dei dati: all’interno dell’enorme mole di informazioni generalmente immagazzinate nei database è necessario effettuare una prima scrematura che permetta di focalizzare le analisi su un sottoinsieme significativo di dati, al fine di ottimizzare le successive attività di elaborazione ed inferenza.
- Preelaborazione delle informazioni: all’esito dei due punti precedenti, è necessario effettuare una ulteriore attività di “affinamento” e pulizia di dati; in tale fase sono usualmente separati i dati validi da quelli “inutili”, è adottata una scelta sulle modalità di trattamento dei campi incompleti o vuoti ed è effettuata la selezione definitiva delle informazioni fondamentali ai fini della generazione del modello ideale di riferimento;
- Trasformazione: nel caso in cui il formato con il quale sono rappresentati i dati non sia ritenuto valido per essere analizzato in maniera efficiente, è necessario avviare un processo di conversione finalizzato a rendere omogenee e opportunamente trattabili tutte le informazioni necessarie all’acquisizione di nuova conoscenza;
- Data mining: si tratta, come è di tutta evidenza, del passaggio più importante nel quale è effettuata la selezione degli strumenti maggiormente idonei in rapporto alla situazione contingente ed è analizzata in profondità la banca dati al fine di raggiungere gli obiettivi prefissati. Il data mining solitamente si compone di molteplici sottopassaggi, che sono eseguiti diverse volte con l’obiettivo di affinare la procedura e verificare ciclicamente i risultati raggiunti;
- Interpretazione dei risultati: in tale fase, si verifica se i dati ottenuti attraverso le attività descritte in precedenza siano effettivamente utili e, in caso di necessità, si avviano nuove iterazioni con l’obiettivo di ottimizzare l’intero processo.
- Visualizzazione dei risultati in un formato comprensibile: si tratta, invero, di un passaggio spesso sottovalutato ma, al contrario, estremamente importante in quanto i dati estratti devono necessariamente essere presentati in un formato immediatamente intellegibile dai soggetti chiamati ad assumere, in ultima battuta, le decisioni strategiche.
Alla luce di quanto indicato finora, il data mining, all’interno del processo di “Knowledge Discovery in Databases”, si sostanzia nell’effettuazione di una vera e propria analisi matematica e scientifica su banche dati di grandi dimensioni, con una duplice finalità:
- l’estrazione, con tecniche analitiche di ultima generazione, di informazioni implicite, nascoste o non facilmente identificabili, con l’obiettivo di renderle disponibile e direttamente utilizzabili nel contesto aziendale, scientifico o politico di riferimento;
- l’esplorazione, eseguita in modo automatico o semiautomatico su grandi quantità di dati, con l’obiettivo di identificare comportamenti e schemi ricorrenti e significativi che possano in qualche modo essere predetti anche nel lungo periodo.
Come funziona il data mining, e come “minare” (o estrarre) i dati
Alla luce delle precedenti considerazioni, è possibile affermare che il data mining sia costituito da un insieme di regole, strumenti, metodologie e tecniche finalizzate a trattare, elaborare e analizzare informazioni tra loro differenti e provenienti da fonti anche non direttamente connesse tra loro.
In estrema sintesi, pertanto, il data mining può fornire due macrocategorie di risultati:
- Modelli descrittivi, che servono soprattutto a comprendere ed esplicitare le relazioni, le dipendenze, le connessioni causa-effetto esistenti all’interno di un set di dati; una declinazione concreta di tale funzionalità è data dalla ricerca scientifica che tenta, attraverso studi, approfondimenti ed esperimenti, di ricostruire il funzionamento di sistemi complessi come, ad esempio, quelli del corpo umano per prevenire eventi dannosi, curare malattie, orientare i comportamenti, etc.
- Modelli predittivi, che consentono di ottenere in anticipato una stima quanto più possibile veritiera partendo dalle informazioni già a disposizione. Si pensi, a titolo di esempio, alla meteorologia che punta, tra l’altro, a prevedere le variazioni atmosferiche in un intervallo di tempo futuro più o meno ampio.
In tale contesto, il data mining permette, innanzitutto, di realizzare attività di fondamentale importanza quali:
- classificazione, ossia l’individuazione di insiemi di elementi accomunati dal possesso di specifiche caratteristiche condivise;
- clusterizzazione (o segmentazione), sintetizzabile nell’identificazione di gruppi di elementi omogenei, che a differenza di quanto avviene nella classificazione, sono basati su regole occulte fino al momento della loro scoperta;
- associazione, ossia l’individuazione di nessi casuali ma ricorrenti estrapolabili dai dati racchiusi in una banca dati con l’obiettivo di individuare anomalie;
- regressione, che rappresenta un’attività simile alla classificazione, che utilizza un numero estremamente elevato di variabili;
- individuazione di serie storiche, ossia l’esecuzione di complesse regressioni che inglobano variabili temporali (date, variazione dei tassi di interesse, etc) e quindi particolarmente utili a scopo predittivo;
- scoperta di sequenze, ossia l’identificazione di dipendenze che integrano il concetto di associazione con un fattore di correlazione temporale, che permette di rilevare la circostanza per la quale ad un determinato evento (quale l’acquisto di un dispositivo elettronico) seguano ulteriori attività (quali la ricerca, in un determinato arco temporale successivo, di prodotti compatibili con l’oggetto acquistato in precedenza).
Il data mining, alla luce di quanto finora descritto, può essere considerato come un processo estremamente articolato e complesso ma anche “settoriale” e “specialistico”: esulano dall’ambito del data-mining, ad esempio, tutte le attività di reperimento e raccolta dai dati, così come tale insieme di metodologie è solo in parte sovrapponibile a procedimenti derivanti dalla statistica.
Tecniche ed esempi di data mining
Per ottenere i risultati prefissati, che consistono nell’estrazione di nuova conoscenza da informazioni in qualche modo già residenti all’interno di banche dati, è necessario utilizzare una serie di tecniche e architetture estremamente settoriali che permettono di “minare” i dati, tra le quali meritano una menzione particolare le reti neurali artificiali, gli alberi di decisione e i cosiddetti “classificatori Naive Bayes”.
Reti neurali artificiali
Una prima tecnica di fondamentale importanza nel contesto del data mining è rappresentata dalle cosiddette “reti neurali” artificiali che, ispirandosi agli omonimi circuiti biologici, costituiscono modelli computazionali composti da “neuroni” digitali finalizzati alla risoluzione di problemi ingegneristici estremamente complessi e articolati.
In estrema sintesi, le reti neurali utilizzano, in base alla problematica e allo specifico contesto di riferimento, uno dei seguenti paradigmi:
- apprendimento supervisionato (conosciuto anche come “supervised learning”), che risulta particolarmente utile qualora si disponga di un insieme di dati per l’addestramento, che include esempi di “ingressi” associate alle “uscite” corrispondenti: in tal modo la rete può in prima battuta imparare ad inferire la relazione che lega ogni elemento e, successivamente, può essere “addestrata” mediante un opportuno algoritmo di pesatura. Se l’addestramento ha successo, la rete impara a riconoscere la relazione incognita che lega le variabili di ingresso a quelle di uscita ed è quindi in grado di effettuare previsioni anche nei casi in cui il risultato non sia noto a priori. L’obiettivo di fondo dell’apprendimento supervisionato è quello di predire, grazie ad una adeguata capacità di generalizzazione, il valore dell’uscita per ogni ingresso valido, basandosi soltanto su un numero limitato di esempi di corrispondenza, ossia su un insieme ristretto di coppie input-output;
- apprendimento non supervisionato (o “unsupervised learning”), che si fonda, invece, su algoritmi di addestramento che modificano i pesi della rete facendo esclusivamente riferimento alle sole variabili di ingresso. Tali algoritmi tentano di classificare i dati in input e di individuare insiemi (o “cluster”) rappresentativi, facendo uso tipicamente di metodi topologici o probabilistici. L’apprendimento non supervisionato è anche impiegato per sviluppare tecniche di compressione dei dati;
- apprendimento per rinforzo (o “reinforcement learning”), che si prefigge, infine, lo scopo di individuare un certo “modus operandi”, a partire da un processo di osservazione dell’ambiente esterno; in particolare, tale tecnica analizza la reazione prodotta dal sistema in risposta ad ogni evento provando a identificarne le cause ed i meccanismi di funzionamento. L’apprendimento con rinforzo differisce da quello supervisionato poiché non sono mai fornite al sistema coppie input-output di esempi noti né si procede alla correzione esplicita di azioni subottimali.
Alberi di decisione
Un albero di decisione è un modello predittivo che assume la forma di un grafo, nel quale:
- un nodo rappresenta una specifica variabile;
- un arco verso un nodo figlio descrive un possibile valore per la variabile rappresentata dal padre;
- una “foglia” rappresenta il valore “predetto” per la variabile obiettivo, che è calcolato a partire dai valori delle altre proprietà derivanti dal cammino (path) dal nodo radice (root) al nodo foglia.
Normalmente un albero di decisione è costruito utilizzando tecniche di apprendimento a partire dall’insieme dei dati iniziali (data set), che può essere, a sua volta, diviso in due sottoinsiemi:
- il training set sulla base del quale si crea la struttura dell’albero;
- il test set che viene utilizzato per testare l’accuratezza del modello predittivo così creato.
Naive Bayes
Un Naive Bayes è un particolare classificatore che, utilizzando l’omonimo teorema di Bayes, determina la probabilità di un elemento di appartenere o meno a una certa classe in funzione dei suoi attributi.
Una particolarità di tale strumento è rappresentata dal fatto che ogni caratteristica viene valutata in autonomia, ossia che le probabilità di un attributo di risultare appartenente a una classe non dipendono dalla relazione con altre proprietà.
Tra i principali vantaggi di tale classificatore rientrano l’insensibilità al “rumore” (ossia ai dati errati, inutili, incompleti) e una buona efficienza anche in presenza di informazioni incomplete.
Strumenti e software per il data mining
A ulteriore dimostrazione dell’importanza e della pervasività del data mining nel contesto dei sistemi informativi moderni, sono innumerevoli ed estremamente usati gli strumenti finalizzati a creare nuova conoscenza applicando le tecniche sopra descritte, che devono naturalmente essere declinate ed adattate rispetto allo specifico campo di applicazione.
Di seguito è proposta una carrellata, certamente non esaustiva, di software, piattaforme digitali e strumenti dedicati al mondo del data mining.
Xplenty

Video
 | Sito ufficiale | Linguaggio di programmazione | Sistemi Operativi | Costi/Licenze |
| https://www.xplenty.com/ | Java | Multipiattaforma (Windows, macOS, Linux) | Non ha licenze gratuite; Concede un periodo di trial; Propone diverse opzioni a pagamento. | |
| Xplenty si rivolge specificatamente a tutti coloro che non si occupano prevalentemente di informatica e, in particolare, non possiedono competenze e conoscenze nell’ambito della programmazione e della scrittura del codice. L’obiettivo di fondo è quello di semplificare e rendere quanto più veloce e diretto possibile il processo di manipolazione di dati per fornire risposte in tempi rapidi ad aziende operanti nei più disparati settori produttivi o commerciali. Attraverso un’interfaccia grafica intuitiva e moderna, la piattaforma permette di aggregare i dati provenienti da più fonti, nel rispetto della privacy e della protezione dei dati personali. 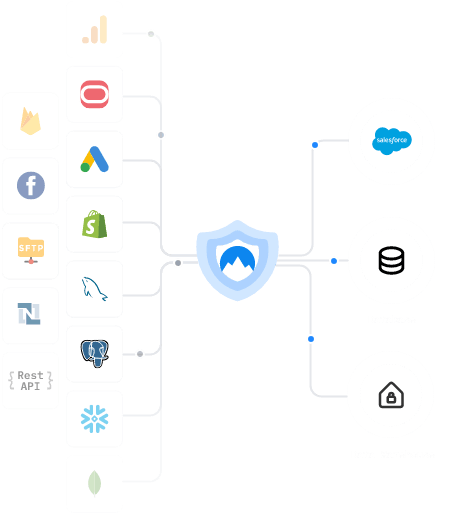 Fonte: https://www.xplenty.com/ | ||||
Rapid Miner

Video
 | Sito ufficiale | Linguaggio di programmazione | Sistemi Operativi | Costi/Licenze |
| https://rapidminer.com/ | Java | Multipiattaforma (Windows, macOS, Linux) | Viene fornita una versione Freeware ma è possibile acquistare licenze con funzionalità aggiuntive a pagamento | |
| Basato su un motore Java, Rapid Miner Studio è uno strumento “open-source” specializzato nel text mining, ossia in quella tecnica che utilizza l’elaborazione del linguaggio naturale per trasformare il testo libero, non strutturato, di documenti/database in dati strutturati e normalizzati, nell’apprendimento automatico, che permette alla piattaforma di acquisire in maniera autonoma nuova conoscenza, e nell’analisi predittiva, che permette di analizzare fatti storici e attuali e fornire predizioni sul futuro o su eventi sconosciuti. Inizialmente conosciuto come YALE, ossia “Yet Another Learning Environment”, si è imposto, nel corso del tempo, come uno dei software maggiormente utilizzati nell’ambito del data mining, tanto che nel 2014 un sondaggio lo pose in cima alla speciale classifica degli strumenti più famosi. RapidMiner, in particolare, si compone di tre moduli (RapidMiner Studio, RapidMiner Server e RapidMiner Radoop) che gli permettono di supportare tutti i passaggi e le fasi del processo di data mining, partendo dalla preparazione dei dati fino ad arrivare alla rielaborazione dei risultati ed all’analisi predittiva. | ||||
Knime

Video
 | Sito ufficiale | Linguaggio di programmazione | Sistemi Operativi | Costi/Licenze |
| https://www.knime.com/ | Java | Multipiattaforma (Windows, macOS, Linux) | Distribuito con licenza opensource GPL. | |
| Nato da un progetto condotto dall’Università di Costanza, Knime si presenta come piattaforma open source con licenza GPLv3 di analisi dati, reportistica e integrazione. Grazie alla presenza di oltre 1000 moduli e pacchetti, Knime si adatta agli scenari più disparati e consente di analizzare dati anche estremamente differenti tra loro. E’ particolarmente apprezzato per l’analisi dei dati integrativa e per le funzionalità di pre-elaborazione delle informazioni, generalmente conosciute come tecniche di ETL (Extraction, Trasformation, Loading). Interamente scritto in Java all’interno dell’ambiente integrato di lavoro “Esclipse”, Knime si è affermato soprattutto nell’ambito farmaceutico, nel settore dei dati finanziari e nell’ambito della cosiddetta “Business Intelligence”. | ||||
Apache Mahout

Video
 | Sito ufficiale | Linguaggio di programmazione | Sistemi Operativi | Costi/Licenze |
| https://mahout.apache.org/ | Java | Multipiattaforma (Windows, macOS, Linux) | Distribuito con “Apache License 2” (opensource) | |
| Secondo quanto indicato sul sito ufficiale, Apache Mahout è un framework di algebra lineare distribuita basato su “Scala DSL” progettato per consentire a matematici, statistici e “data scientist” di implementare rapidamente i propri algoritmi. E’ stato ideato per integrarsi in maniera nativa con un altro celebre strumento della Apache Software Foundation, rappresentato dal software opensource per il calcolo distribuito sviluppato dall’AMPlab della Università della California, conosciuto come “Apache Spark”, ma è perfettamente integrabile con altri strumenti di back-end. Si tratta, com’è di tutta evidenza, di un framework fortemente specialistico che si rivolge primariamente ad esperti del settore con l’obiettivo di fornire soluzioni altamente efficienti nell’ambito del data-mining. | ||||
WEKA

Video
 | Sito ufficiale | Linguaggio di programmazione | Sistemi Operativi | Costi/Licenze |
| https://www.cs.waikato.ac.nz/ml/weka/ | Java | Multipiattaforma (Windows, macOS, Linux) | Distribuito con licenza opensource GPL | |
| Progettato dall’Università neozelandese di Waikato, WEKA fornisce una raccolta di algoritmi di apprendimento automatico per attività di data mining e contiene strumenti per la preparazione dei dati, la classificazione, la regressione, il clustering, l’estrazione di regole di associazione e la visualizzazione. Weka, in particolare, è un ambiente software interamente scritto in Java, che permette di applicare metodi di apprendimento automatici (learning methods) ad un set di dati (dataset) e analizzarne il risultato, ottenendo previsioni di scenari futuri. | ||||
SAS

Video
 | Sito ufficiale | Linguaggio di programmazione | Sistemi Operativi | Costi/Licenze |
| https://www.sas.com/it_it/home.html | SAS Language | Windows, macOS, Linux | Presenta diverse opzioni a pagamento. Prevista una versione gratuita, su richiesta, per gli istituti di istruzione | |
| Può essere considerato come una vera e propria eccellenza nel campo del data mining grazie a una serie di funzionalità avanzate che permettono alle aziende di elaborare grandi quantità di dati in maniera estremamente efficiente. SAS è particolarmente apprezzato per la capacità di implementare modelli predittivi, per le funzionalità di visualizzazione interattiva dei dati e per gli ottimi risultati di presentazione di grandi moli di dati. Implementato e commercializzato dall’omonimo istituto statunitense, è utilizzato nel settore farmaceutico, dove è diventato un vero e proprio standard de facto. E’ prevista una versione gratuita per gli enti pubblici ma in generale è distribuito con licenze a pagamento che lo rendono anche uno degli strumenti aziendali più costosi nell’ambito del data mining. | ||||
Applicazioni del data mining in azienda
Come anticipato in precedenza i settori di applicazione del data mining sono innumerevoli ed abbracciano praticamente tutte le sfere dell’attività umana spaziando dal marketing per arrivare all’economia, alla finanza ma anche alla scienza, alle tecnologie dell’informazione e della comunicazione, alle statistiche, all’industria e praticamente a ogni altro ambito nel quale è necessario trattare, analizzare ed elaborare dati con l’obiettivo di ottenere nuova conoscenza.
All’interno del vasto ed articolato universo delle tecniche e delle metodologie di data mining, di seguito è proposta una selezione di alcune applicazioni particolarmente interessante e diffusi in differenti ambiti professionali, commerciali, scientifici e industriali:
- Clusterizzazione della clientela: è una tecnica per l’individuazione di tipologie di acquirenti accomunati da abitudini di acquisto e caratteristiche sociodemografiche quali, a titolo di esempio, l’età anagrafica, la provenienza, il titolo di studio, etc. Si tratta, in estrema sintesi, di una tecnica utile per segmentare la propria banca dati e inviare, ad esempio, una certa promozione al target giusto per quel prodotto o servizio (giovani, laureati, commercianti, pensionati, etc).
- Regression Analysis: si tratta di una tecnica statistica finalizzata a quantificare la relazione tra le variabili. In particolare, nell’analisi di regressione semplice, c’è una variabile dipendente (ad esempio le vendite) da prevedere e una variabile indipendente, i cui valori sono in genere quelli che si presume causino o determinino i valori della variabile dipendente. Provando a effettuare un esempio, assumendo che la quantità di capitale investita per pubblicizzare un prodotto determini l’importo delle sue vendite, è possibile utilizzare l’analisi di regressione per quantificare in termini numerici la relazione tra pubblicità e vendite.
- Customer retriever: analizzando il comportamento dei clienti di un determinato marchio, è possibile identificare i soggetti maggiormente soggetti al rischio abbandono, in quanto, ad esempio, non perfettamente soddisfatti dei prodotti o dei servizi di assistenza e customer care, e adottare le conseguenti strategie per impedirlo, attraverso promozioni mirate, scontistiche particolari o anche modifiche alla produzione e alla commercializzazione;
- Market basket analysis: è un processo di analisi di affinità che studia le abitudini di acquisto dei clienti nella vendita al dettaglio, trovando associazioni su diversi prodotti comprati, permettendo, in ultima battuta, l’adozione di strategie di marketing fortemente personalizzate.
- Rilevamento di frodi: le frodi che coinvolgono telefoni cellulari, reclami assicurativi, dichiarazioni dei redditi, transazioni con carta di credito, appalti pubblici, ecc. rappresentano problemi significativi per i governi e le imprese tanto che sono state implementate specifiche tecniche di analisi finalizzate ad individuare comportamenti sospetti e potenzialmente fraudolenti.
Particolarmente interessante in tale ambito è il progetto Arachne promosso dalla Commissione Europea con l’obiettivo di sostenere le autorità di gestione nei controlli che svolgono nell’ambito dei fondi strutturali.
- Previsioni sui trend degli indici azionari: correlando tra loro i dati connessi all’andamento della borsa, è possibile individuare i titoli sui quali investire nel breve periodo al fine di ottimizzare gli investimenti;
- Interazioni fra mercati finanziari: in mondo sempre più globalizzato e interconnesso, il data mining è utilizzato anche per predire l’influenza dell’andamento generale dei mercati su determinate zone geografiche o anche su particolari tipologie di prodotti e servizi.
- Nel campo della cosiddetta “digital healthcare”, ossia della “medicina digitale”, sempre più ricercatori sostengono che, utilizzando il data mining, è possibile individuare i percorsi di cura maggiormente adatti ai pazienti e creare dei veri e propri piani di trattamento in grado di individuare la metodologia migliore per curare persone con una determinata patologia.
Attraverso l’analisi di migliaia di risultati, sarebbe anche possibile migliorare le diagnosi arrivando, ad esempio, a calcolare l’aspettativa di vita di un determinato paziente in base a risultati di test di routine che, se valutati singolarmente, non consentirebbero di ottenere un quadro definito della situazione clinica ma che, confrontati con miliardi di altri dati similari provenienti da tutto il mondo, potrebbero condurre all’individuazione precoce di patologie anche severe.
Un altro significato di mining: i bitcoin e la blockchain
Ampliando il concetto di mining e affrontandolo in senso lato, ossia trascendendo dalle tematiche e dai confini finora descritti, una menzione particolare meritano, soprattutto per l’importanza e la celebrità acquisita nel corso degli ultimi anni, le “monete virtuali”, quali i Bitcoin, e la blockchain, che in qualche modo rappresenta l’elemento fondamentale per la generazione, la gestione e l’implementazione delle cosiddette “criptovalute”.
Nel contesto dei bitcoin, in particolare, il processo di “mining” può essere descritto come l’insieme delle attività finalizzate a “estrarre” monete virtuali grazie all’utilizzo di super-calcolatori e all’impiego della blockchain, che, in estrema sintesi, si sostanzia in un registro informatico transnazionale, sicuro, condiviso da tutti i soggetti che operano all’interno di una rete distribuita di calcolatori elettronici, in grado di registrare e archiviare tutte le transazioni che avvengono all’interno della rete, eliminando, di fatto, la necessità della presenza di terze parti “fidate”.
La blockchain, invero, è un’implementazione concreta dei registri distribuiti o “Distributed Ledger Technology” (DLT), che rappresentano particolari database allocati su più server sincronizzati tra loro, con il fine ultimo di garantire l’immutabilità delle informazioni memorizzate e la registrazione sicura di tutte le operazioni effettuate.
Nonostante si tratti di una tecnologia giovane ed ancora in via di sviluppo, la blockchain è stata già integrata in alcuni progetti lanciati dalla pubblica amministrazione italiana nel contesto del processo di digitalizzazione dell’articolata macchina burocratica statale.
In particolare, il ministero dell’Istruzione, dell’Università e della Ricerca sta lavorando da alcuni anni ad un interessante progetto finalizzato a permettere, sfruttando le potenzialità della Blockchain, la convalida dei titoli di studio dei rifugiati, confermando l’Italia come uno dei Paesi leader nella sperimentazione dello “European Qualifications Passport for Refugees“, ossia il progetto europeo finalizzato a ricostruire il percorso di formazione dei rifugiati e riconoscere ufficialmente le loro competenze in tutti i Paesi dell’Unione.
Particolarmente rilevante è, sotto questo profilo, l’attività svolta dall'”Osservatorio italiano sulle politiche in materia di blockchain“, nato grazie a una partnership strategica tra soggetti istituzionali di assoluto prestigio quali l’Università Roma Tre, il Consiglio nazionale dell’economia e del lavoro (CNEL), l’Agenzia nazionale per le politiche attive del lavoro (Anpal) e il Garante della Privacy, che ha proposto, tra l’altro, di creare il fascicolo elettronico del lavoratore basato sulla blockchain.
Conclusioni
Il Data mining sta assumendo un ruolo fondamentale all’interno di quasi tutti gli ambiti professionali e aziendali in quanto consente di elaborare, analizzare, esplicitare e valorizzare le informazioni e i dati che rappresentano, ormai, una vera e propria “materia prima” sulla quale costruire i processi organizzativi oltre che uno strumento indispensabile per l’adozione di decisione strategiche e una fonte inestimabile di guadagno.
Si tratta, in estrema sintesi, di un insieme di tecniche e di processi multidisciplinari che abbracciano la matematica, la statistica, l’algebra lineare, l’informatica e l’elettronica per divenire un elemento basilare dell’ormai celebre “data science”, ossia della scienza focalizzata sull’analisi dei dati.
Nel corso del tempo sono state implementate e affinate diverse tecniche di estrazione di dati quali le reti neurali, gli alberi di decisione e i “classificatori”, tra i quali particolare rilievo hanno assunto quelli basati sull’algoritmo di Bayes.
Con l’obiettivo di diffondere il data mining all’interno delle aziende e al di fuori dei confini spesso angusti dei laboratori di ricerca, molte comunità di programmatori e diverse software-house di rilevanza planetaria hanno sviluppato anche programmi e piattaforme moderne e “user-friendly” che consentono oggi a tutti gli interessati di utilizzare le tecniche di elaborazione dei dati in maniera semplice, diretta e rapida.
In tale situazione, le applicazioni concrete delle tecniche di data mining ha subito una repentina accelerazione raggiungendo ambiti anche estremamente differenti e divergenti tra loro come il marketing, la medicina, la meteorologia, la finanza ma soprattutto proponendosi come una base imprescindibile di conoscenza per ogni tipologia di attività sia pubblica che privata.
















