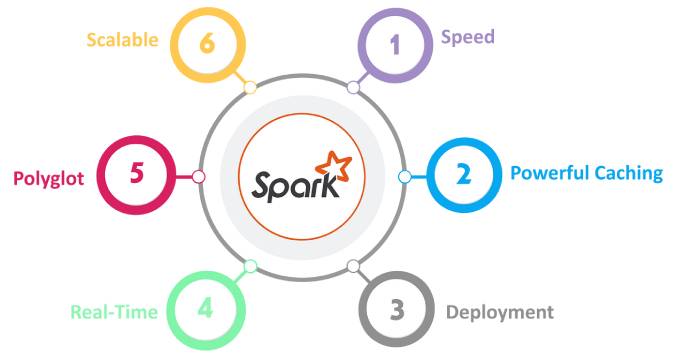
Nel panorama dei motori Open source di elaborazione dei dati spicca Apache Spark il quale, attualmente almeno, sta distanziando le altre soluzioni disponibili. Il tema più ricorrente è la presunta battaglia tra Apache Spark e Apache Hadoop ma si tratta di uno scontro che avviene in una trincea tutta letterale, perché i due framework hanno peculiarità diverse e, non di rado, sono usati in modo complementare.
Approfondimento
Apache Spark: superare le sfide dell’elaborazione distribuita dei dati
Apache Spark si fregia del titolo di piattaforma leader SQL su larga scala. In dote ha anche la velocità e la flessibilità, l’elaborazione batch e la vocazione per il Machine learning. Ecco quali sono le sue prerogative e perché si è guadagnato spazio in breve tempo
Pubblicato il 24 ott 2023
Continua a leggere questo articolo


Speciale Digital Awards e CIOsumm.it
Tutti
Update
Keynote
Round table
Filtra per topic















