Nel futuro delle Cose connesse, dell’Internet of Things, i numeri sono di quelli che fanno impressione: miliardi di sensori per milioni di miliardi di dati. La sfida dell’IoT, in fondo, sta tutta qui: nella capacità di trasformare questi dati in informazioni, le informazioni in analisi, le analisi in azioni in grado di migliorare i processi di business.
Uno, in particolare, è di particolare interesse per tutti gli ambiti toccati dalla “rivoluzione” dell’IoT: la manutenzione predittiva, che impone un cambio di paradigma, dalla reazione alla prevenzione, con un sguardo puntato non più a ciò che è accaduto, ma a ciò che potrebbe accadere in assenza di interventi specifici e mirati.
I benefici sono facilmente intuibili: si parla di una riduzione dei costi di manutenzione degli impianti, di una diminuzione dei tempi di downtime, di un calo degli investimenti in capitale, derivante dall’allungamento della vita utile dei dispositivi.
Per maggiori approfondimenti su Big Data, Data Science e sul lavoro dei Data Scientist scarica il white paper
Al lavoro con i data scientist: una guida per cogliere le opportunità dei big data
Indice degli argomenti
I Big Data al servizio della predictive maintenance dell’IoT
La predictive maintenance richiede analisi avanzate dei dati operativi e dei dati di business, con l’obiettivo di determinare le condizioni degli asset e intervenire dove serve e quando serve. Richiede analisi direttamente derivanti dalla data science, intesa come ambito multidisciplinare nel quale confluiscono metodologie quantitative, come statistica, data mining, ricerca operativa, machine learning, con l’obiettivo di trasformare i dati in conoscenza.
Nessuna di queste discipline è nuova di per sé: ciò che cambia è la loro relazione con l’IoT e con il numero di dati e di variabili che entrano in gioco.
Quando parliamo di manutenzione predittiva, data science e machine learning sono gli strumenti che consentono di identificare le anomalie nell’ambito di set di dati molto grandi – un po’ come trovare il famoso ago nell’altrettanto famoso pagliaio -, di effettuare le analisi anche su eventi molto rari, di effettuare analisi multivariata su grandi quantità di dati e di variabili. Supportano lo streaming di dati, sono in grado di consentire la visualizzazione di grandi volumi di dati.
Le sfide per la data science, e per i data scientist soprattutto, sono sempre le stesse: quali dati sono rilevanti? I dati sono interessanti da un punto di vista qualitativo? Il modello derivante dall’algoritmo è quello giusto per trasformare una relazione di tipo matematico in un nesso causale?
Quali analisi per la manutenzione predittiva?
Ecco dunque che dalla data science, applicata alla predictive maintenance, possono derivare diverse tipologie di analisi.
SAP, che al tema ha dedicato un lungo documento dal titolo “Data Science and Machine Learning in Internet of Things anche Predictive Maintenance”, le ha raggruppate in 5 categorie:
- Trend
Quali sono le tendenze nei dati, come si comporta, nel tempo, un sensore? C’è qualche processo fuori controllo? Qual è la vita utile prevista per ciascun componente? - Relazioni
Quali sono le cause principali di un gusto a una macchina? - Segmentazione
È possibile segmentare o raggruppare chiaramente i dati? - Associazioni
Quali sono le correlazioni tra i dati? Un degrado nelle performance della macchina e il guasto possono essere correlati? - Anomalie
Quali sono le anomalie e quali i valori insoliti? Sono da considerare come errori o come effettivi cambiamenti nel comportamento di una macchina o di un sensore?
Parliamo dunque di relazioni, con l’obiettivo di costruire un modello che definisca le relazioni tra gli input e gli output, mentre le anomalie possono essere eventi che anticipano una rottura.
A questi cinque gruppi principali, si possono poi aggiungere ulteriori attività, ad esempio simulazioni, ottimizzazioni, analisi di dati non strutturati, mining.
In tutto questo contesto, non deve mancare la competenza specifica del settore nel quale si opera, senza la quale, ad esempio, sarebbe impossibile utilizzare gli eventi rari in una logica di manutenzione predittiva. Proprio per la loro rarità, a questi eventi si associano pochi dati, difficilmente storicizzabili. Ecco allora che la competenza degli esperti è quella che consente di inserire anche questi eventi in un processo di analisi predittiva.
Nella sua visione, SAP ha così schematizzato il processo che lega data science e manutenzione predittiva.
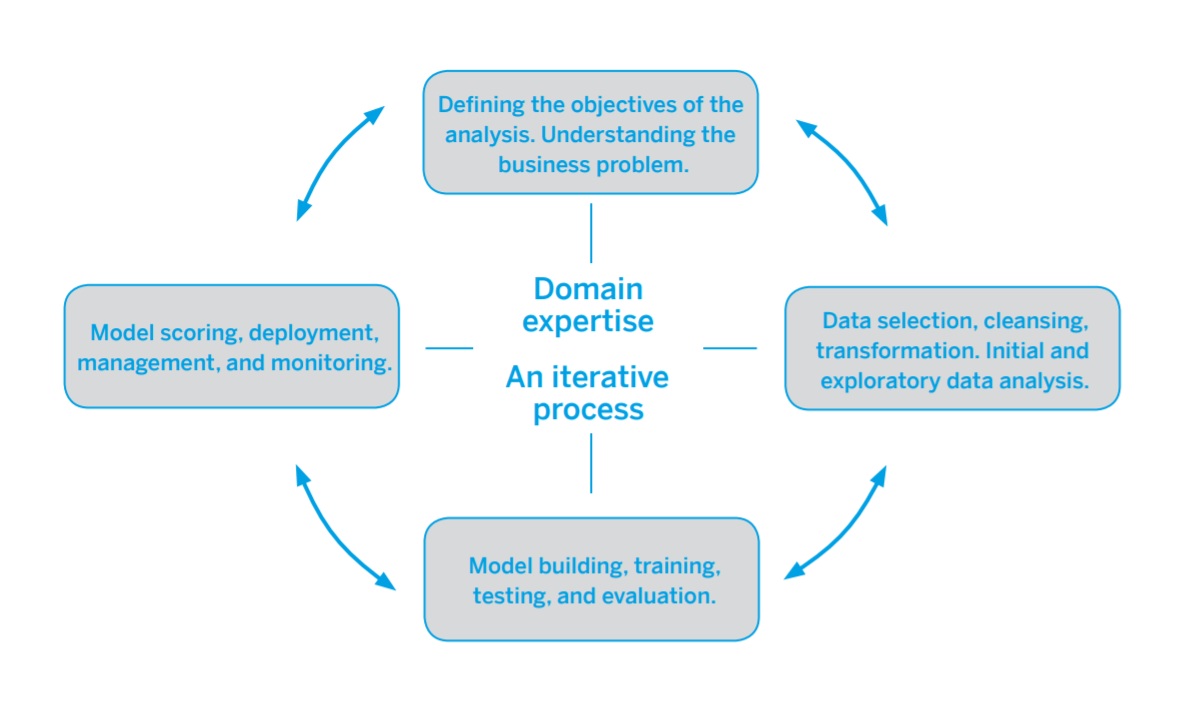
Appare chiaro, da questa immagine, che non si possa fermarsi agli algoritmi: l’attività principale, nell’ambito della data science, è nell’identificazione, accesso, preparazione dei dati per l’analisi.
Tuttavia, senza dati rilevanti e di qualità nessuna analisi è possibile.
Certo, l’accuratezza dell’algoritmo è importante, ma altrettanto cruciale è la comprensione del modello: se l’obiettivo è migliorare i processi di business, è indispensabile comprendere perché dalle analisi arrivino indicazioni di cambiamenti da apportare. Altrimenti nessuna azione diventa possibile.
Nessun data scientist è un’isola
Torniamo a parlare dunque di attività collaborative, che prevedono l’intervento di diverse figure professionali.
Il data scientist non basta.
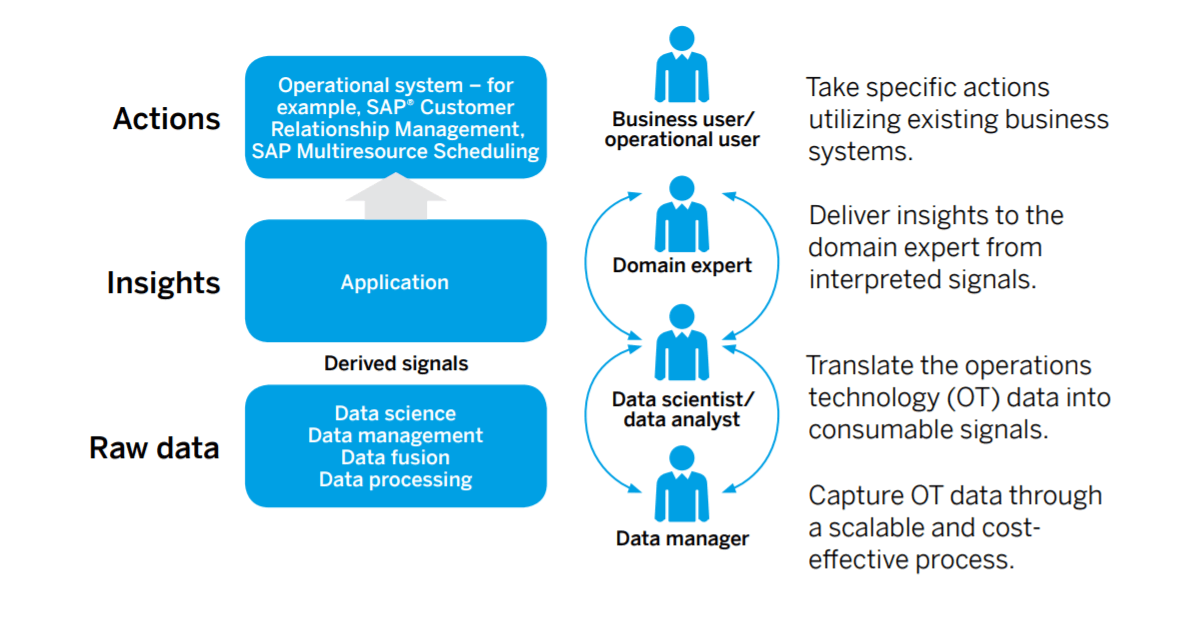
Nella sua visione SAP identifica 4 figure professionali a vario titolo coinvolte.
Si parte dal data manager, il cui compito è acquisire i dati dell’OT attraverso processi scalabili e cost-effective; i dati OT in segnali vengono tradotti in segnali “consumabili”, che passano al data scientist o al data analyst, che a loro volta passano all’esperto gli insight derivanti dalle loro analisi. Infine, dall’esperto si passa all’operatore di campo, che traduce le indicazioni in azioni specifiche.