
La confusion matrix, o matrice di confusione, è un mezzo dedicato all’analisi degli errori di un modello di machine learning (ML). Ecco una guida pratica per valutare il modello di classificazione.

Indice degli argomenti
Confusion matrix per valutare le prestazioni di un modello di classificazione
La confusion matrix fornisce una panoramica dettagliata delle performance del modello, consentendo di identificare eventuali errori ricorrenti e di adottare eventuali misure correttive.
Permette di valutare la qualità delle previsioni del modello di classificazione. Nei dettagli, la matrice sottolinea dove sbaglia il modello, in quali istanze risponde in maniera meno performante e in quali invece offre migliori prestazioni.
È infatti importante valutare il modello non solo in base all’accuratezza, ma anche in considerazione delle altre metriche. L’obiettivo è quello di avere una visione più completa delle sue prestazioni.
La matrice di confusione è uno strumento molto utile per valutare le prestazioni di un modello di classificazione. Rappresenta una tabella che mostra il numero di predizioni corrette o errate, compiute dal modello su un set di dati di test.
La confusion matrix è organizzata in quattro categorie: True Positives (TP), True Negatives (TN), False Positives (FP) e False Negatives (FN).
La prima rappresenta il numero di casi in cui il modello ha offerto una previsione corretta di una classe positiva.
True Negatives (TN) costituisce invece il numero di casi in cui il modello ha correttamente predetto una classe negativa.
La terza categoria rappresenta il numero di casi in cui il modello ha erroneamente predetto una classe positiva, quando in realtà era negativa. Si tratta di un falso allarme.
False Negatives (FN), infine, indica il numero di casi in cui il modello ha erroneamente predetto una classe negativa quando in realtà era positiva. Si tratta quindi di una mancata identificazione.

Video: Confusion Matrix
Come utilizzare la confusion matrix per migliorare la precisione delle previsioni
Il filtro antispam sulla posta elettronica in arrivo è un perfetto esempio di classificatore binario, in cui le classi sono due: sì o no. Il modello infatti ha lo scopo di decidere se la mail in entrata è spam oppure no.
La matrice di confusione vede righe in cui sono indicate le classi effettive, quelle delle risposte corrette. Nelle colonne sono presenti invece le classi di previsione, quelle delle risposte del modello. Ma la confusion matrix può essere anche multiclasse con tre classi.
Il modello analizza 80 email per classificarle spam/no spam. In 60 casi il modello effettua una classificazione corretta, mentre in 20 sbaglia.
Tuttavia, gli errori e le risposte corrette non sono tutte uguali. Se la classe prevista è Sì e coincide con la classe effettiva, è un caso di true positive (vero positivo) in cui il modello ha fornito una risposta corretta (Sì).
Il secondo casi è quello in cui la classe prevista è No e coincide con la classe effettiva. Il caso è di true negative (vero negativo) e il modello ha offerto la risposta corretta negativa (No).
Il terzo caso è quello del falso positivo, in cui la classe prevista è Sì, ma non coincide con la classe effettiva. Si tratta del modello che ha sbagliato a rispondere Sì.
Se la classe prevista è No, ma non coincide con la classe effettiva, è un caso di falso negativo dove il modello ha sbagliato a rispondere No.
La matrice di confusione semplifica dunque l’analisi degli errori, rendendo palese che il modello non trattiene tutte le email di spam (false negative), ma lascia passare circa 15 messaggi di spam, giudicati validi. Più rari sono invece i falsi positivi: infatti su 80 messaggi, appena 5 email valide sono scambiate erroneamente per spam.

Confusion matrix: metriche di valutazione essenziali
La confusion matrix può servire a calcolare diverse metriche di valutazione, come per esempio il tasso di errore, l’accuratezza, la precisione, il richiamo o sensibilità (Recall) e l’F1-score. Mettendo la confusion matrix e le metriche ad essa associate sotto la lente, è possibile identificare le aree in cui il modello presenta criticità. Così è possibile adottare misure specifiche per aumentare la precisione delle previsioni.
L’error rate è la misura della percentuale di errore delle previsione sul totale delle istanze. Varia da 0 (la previsione migliore) a 1 (lo scenario peggiore).
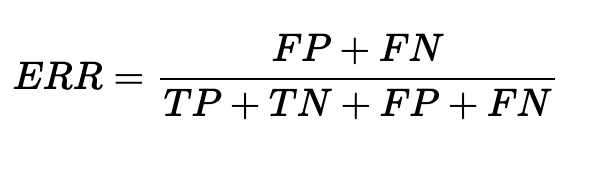
L’accuracy rappresenta la percentuale di predizioni corrette rispetto al totale delle predizioni. L’accuratezza è l’inverso del tasso di errore, dunque varia da 0 (scenario peggiore) a 1 (previsione migliore).
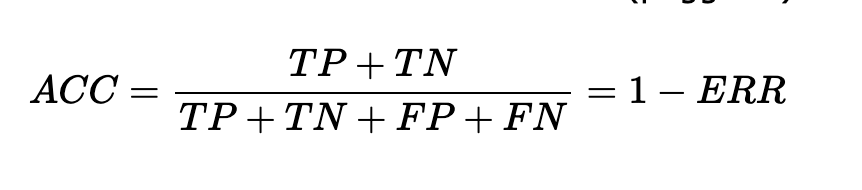
La precisione indica la percentuale di predizioni corrette di classe positiva rispetto al totale delle predizioni di classe positiva.
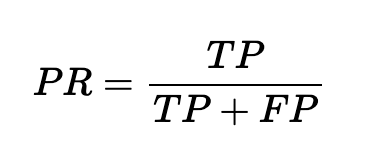
Il Recall costituisce invece la percentuale di predizioni corrette di classe positiva rispetto al totale dei casi di classe positiva. Il richiamo (o recall) o sensibilità (sensitivity) è la quota delle previsioni positive corrette (TP) sul complesso delle istanze positive. Varia da 0 (previsione peggiore) a 1 (scenario migliore).
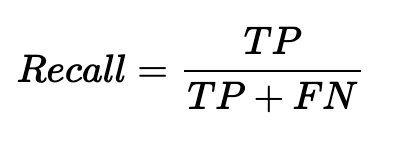
F1-score rappresenta inoltre il punteggio F , la media armonica delle metriche Precision e Recall. Variando da 0 (peggiore) a 1 (migliore), fornisce una misura complessiva delle prestazioni del modello.
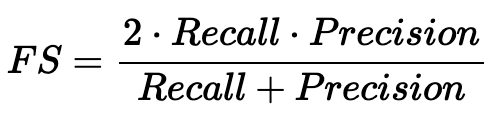
Altre metriche sono infine la specificità (specificity), la percentuale delle previsioni negative corrette (TN) sul totale delle istanze negative. Fra 0 (peggiore) e 1 (migliore). Il tasso dei falsi positivi (False Positive Rate) è la quota delle previsioni positive errate (FP) sul totale delle istanze negative. Fa 0 (migliore) e 1 (peggiore).
La confusion matrix per ottimizzare i parametri del modello di machine learning
La confusion matrix non ottimizza direttamente i parametri del modello di machine learning. Tuttavia fornisce informazioni utili per valutare le prestazioni del modello e guidare l’ottimizzazione dei parametri.
Utilizzandola è possibile ottenere diverse metriche di valutazione del modello, come l’accuratezza, la precisione, il recupero e l’F1-score, da cui trarre una panoramica delle prestazioni del modello su varie classi o categorie.
Attraverso queste metriche, è possibile identificare le aree in cui il modello presenta difficoltà, per esempio se supera una soglia di falsi positivi o falsi negativi, e prendere misure specifiche per correggere gli errori commessi.
Per esempio, se la precisione del modello risulta bassa, significa che sta effettuando molte previsioni erronee della classe positiva. In questo caso, si potrebbe cercare di ottimizzare il modello tagliando il numero di falsi positivi. Per esempio basta modificare la soglia di classificazione o applicare tecniche di bilanciamento delle classi, per ridurre i falsi positivi.
Analogamente, se il modello ha un basso recupero, significa che sta mancando molti casi positivi. In questo caso, si potrebbe cercare di ottimizzare il modello aumentando il recupero, per esempio modificando la soglia di classificazione o attraverso tecniche di campionamento per aumentare la presenza di esempi positivi nel training set.
La confusion matrix offre quindi informazioni preziose per comprendere le prestazioni del modello e guidare l’ottimizzazione dei parametri, consentendo di apportare modifiche mirate al fine di migliorare le previsioni.

Confusion matrix: gestire e interpretare i falsi positivi e i falsi negativi
La gestione e l’interpretazione dei falsi positivi e dei falsi negativi dipendono dal contesto specifico del problema di classificazione e dalle conseguenze delle previsioni errate. Richiedono un’analisi attenta del contesto del problema e delle conseguenze delle previsioni errate, insieme all’utilizzo di metriche di valutazione e tecniche di ottimizzazione appropriate per trovare il giusto equilibrio tra i due tipi di errore.
I falsi positivi si verificano quando il modello classifica erroneamente un’istanza come positiva, quando in realtà appartiene alla classe negativa. I falsi negativi, invece, si verificano quando il modello classifica erroneamente un’istanza come negativa, quando in realtà appartiene alla classe positiva.
Per gestire e interpretare i falsi positivi e i falsi negativi, occorre valutare le conseguenze delle previsioni errate, esaminando le metriche di valutazione. Bisogna regolare la soglia di classificazione, oltre ad utilizzare tecniche di bilanciamento delle classi. Infine è necessario analizzare le caratteristiche e i pattern dei falsi positivi e falsi negativi. Ecco come.
Considerazioni
È importante comprendere le conseguenze delle previsioni errate per le diverse classi. Per esempio, in un sistema di rilevamento di frodi finanziarie, un falso positivo potrebbe causare un inconveniente per il cliente. Invece un falso negativo potrebbe comportare una perdita finanziaria significativa. In base a ciò, si può decidere quale tipo di errore è più critico da minimizzare.
Le metriche come precisione, recupero e F1-score possono aiutare a valutare l’equilibrio tra falsi positivi e falsi negativi. Per esempio, se si vuole ridurre al minimo i falsi positivi, si può cercare di aumentare la precisione. Invece, se si vuole minimizzare i falsi negativi, si può cercare di aumentare il recupero.
Modificare la soglia di classificazione può influire sul numero di falsi positivi e falsi negativi. Aumentando la soglia, si riduce il numero di falsi positivi a favore di un aumento dei falsi negativi, mentre riducendo la soglia si ha l’effetto opposto. Bisogna trovare un compromesso che si adatti alle esigenze specifiche del problema.
Se il dataset è sbilanciato ovvero una classe è rappresentata in modo significativamente diverso rispetto all’altra, i falsi positivi o negativi possono essere più frequenti per la classe meno rappresentata. In questo caso, inoltre, si possono usufruire di tecniche come il campionamento o l’aggiunta di peso alle istanze per bilanciare le classi e ridurre gli errori.
Esaminare le istanze classificate erroneamente può fornire informazioni sulle ragioni degli errori. Si possono cercare caratteristiche comuni tra i falsi positivi o falsi negativi e prendere misure per migliorare il modello, ad esempio aggiungendo nuove feature o raccogliendo più dati per quelle situazioni specifiche.
Confusion matrix: come diagnosticare e risolvere errori comuni
La risoluzione degli errori comuni nella confusion matrix richiede un’analisi attenta delle informazioni fornite dalla matrice stessa.
Per diagnosticare e risolvere gli errori comuni, bisogna seguire alcuni passi. Occorre infatti analizzare la distribuzione dei veri positivi e dei veri negativi, esaminando inizialmente i valori di TP e TN nella confusion matrix. Se questi valori sono bassi rispetto al totale delle istanze, potrebbe essere necessario valutare le caratteristiche del dataset o il modello stesso. Sarebbe anche utile raccogliere ulteriori dati o considerare l’utilizzo di tecniche di feature engineering per migliorare le prestazioni.
Occorre concentrarsi sui valori di FP e FN nella confusion matrix. L’esame delle istanze classificate erroneamente può aiutare ad individuare i pattern o le caratteristiche che stanno provocando errori. È possibile raccogliere ulteriori informazioni sulle istanze errate e considerare l’aggiunta di nuove feature o l’utilizzo di tecniche di pre-elaborazione dei dati per affrontare questi errori specifici.
La soglia di classificazione determina il punto di separazione tra le classi. Modificarla può aiutare a ridurre gli errori comuni. Per esempio, se si desidera ridurre i falsi positivi, si può aumentare la soglia per rendere la classificazione più conservativa. Invece, per ridurre i falsi negativi, si può abbassare la soglia, rendendo la classificazione più inclusiva.
Se il dataset è sbilanciato, con una classe rappresentata in modo significativamente diverso rispetto all’altra, potrebbero verificarsi errori comuni per la classe meno rappresentata. In questo caso, è possibile utilizzare tecniche come il campionamento o l’aggiunta di peso alle istanze per bilanciare le classi e ridurre gli errori comuni.
Infine è importante valutare la qualità e la rappresentatività dei dati. In caso di dati di addestramento incompleti, rumorosi o non rappresentativi del problema reale, ciò potrebbe causare errori comuni. Occorre assicurarsi che la raccolta dati sia di alta qualità, garantendo dati rappresentativi del problema da risolvere.

















