
Big data, intelligenza artificiale, real-time analytics, sono tutte soluzioni che, grazie a una sempre più ampia scelta di servizi on cloud senza costi di upfront, non possono prescindere dall’avere integrato uno o più Data lake, insieme a sistemi più classici di Data warehouse (ove presenti). Negli ultimi dieci anni queste tecnologie si sono diffuse non solo nelle big company, ma in modo crescente anche nelle PMI; entrambe le realtà hanno dedicato questi anni alla sperimentazione, alternando risultati promettenti a costosi fallimenti. Come possiamo far tesoro di questo periodo per capire che cosa non ha funzionato e cercare quindi di direzionare al meglio le strategie future per un effettivo, efficace e reale consolidamento dei Data lake?
Indice degli argomenti
Data lake nella “fossa della disillusione”
Anche se ormai sono anni che se ne parla, riprendiamo brevemente una delle tante definizioni di Data lake:
“un Data lake è un data store che, attraverso l’ingestion in modalità batch o streaming, memorizza in maniera flessibile, scalabile e a bassi costi, dati grezzi di svariata natura al maggior livello di dettaglio possibile che possono quindi essere processati ed acceduti in modalità agile da chiunque in azienda per poter supportare le proprie decisioni o da specialisti per applicare avanzati algoritmi di esplorazione del dato stesso ed estrarne insights difficili da individuare con strumenti classici”.
Quindi un Data lake, differentemente da un Data warehouse/mart dove il dato è pulito, preparato e pronto al consumo, può essere visto appunto come un bacino nel quale confluiscono diversi stream di dati nel quale gli utenti possono immergersi per esaminarli, o prenderne dei campioni utili ai propri scopi.
Nonostante queste caratteristiche si incastrino bene con le attuali esigenze in termini di gestione dei crescenti ed eterogenei flussi dati e con la crescente esigenza di un loro più rapido processamento/consumo, i Data lake sono entrati in quella che la società di consulenza Gartner definisce “fossa della disillusione” (Trough of Disillusionment). Termine coniato per indicare la fase nella quale una tecnologia entra quando, dopo un periodo di primi risultati confortanti e di una buona pubblicità da parte degli addetti ai lavori e della stampa specializzata, le altissime (a volte troppo) aspettative sono largamente non corrisposte dalle reali implementazioni.
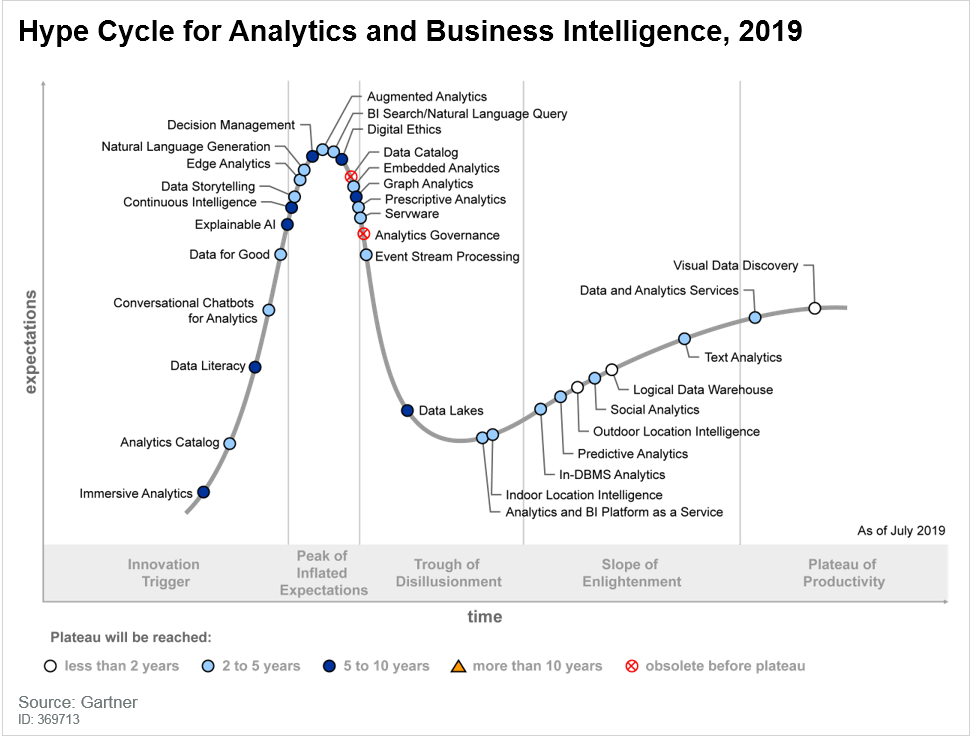
Dal 2012 circa quando è iniziata la corsa ad accaparrarsi tecnologie basate su framework Hadoop, venendo considerati come il silver bullet per far fronte alle esigenze analitiche aziendali, i Data lake stanno vivendo una fase di transizione, nella quale si sta prendendo consapevolezza di quello che davvero possono fare per supportare il business e di quali sono le principali best practices da perseguire e gli errori da non commettere.
Di seguito riportiamo quelli che, dopo una decina di anni di sviluppi su Data lake, sono i principali punti di attenzione sul quale focalizzarsi.
Data lake e Data swamp
Nel 2018 Gartner ha previsto che il 90% dei Data lake verranno considerati come inutili poiché contengono un insieme spropositato di dati senza un chiaro business case associato. Questo fa sì che non portino alcun valore in termini di ROI o di cultura aziendale, tutto ciò in contrasto con gli ottimistici aneddoti professati dalla maggioranza delle organizzazioni. Anche se è difficile capire se questa percentuale sia realistica, è noto come si stiano allargando a macchia di leopardo iniziative di cost review e ci si stia spingendo maggiormente verso concetti di Logical Data warehousing per combinare Data warehouse classici e Data lake. Ci si muove quindi da iniziative Data Lake-centriche, verso soluzioni di maggiore integrazione tra i sistemi esistenti.
Questo accade perché la costituzione di un Data lake è cominciata sotto forma di progetti quasi esclusivamente guidati dai reparti IT senza o con poca condivisione di obiettivi con il business e con la strategia aziendale. Ciò ha portato a situazioni in cui il Data lake venisse considerato come un grande database dal quale andare a prendere dati a seconda del bisogno; portando a grandissimi volumi di dati ingeriti ma non processati, quelli che sono definiti Data swamp, dove i vantaggi portati dalla tecnologia in sé, vengono “diluiti” dal fatto che la porzione di informazioni realmente utili a fini business è molto ridotta.
Avere allineamento tra obiettivi business e scelta del perimetro dati da includere e quindi lavorare, è un passo fondamentale nella Data strategy complessiva.
Architettura e processi
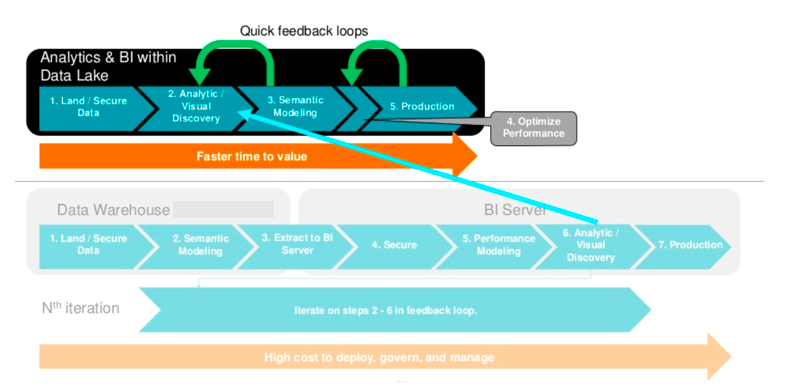
Il più grande errore che è stato fatto nelle prime applicazioni (anche se tutt’ora è una pratica largamente diffusa) aziendali dei Data lake, è stato quello di trattarli come “Data warehouse” su cloud e non come tecnologie che devono essere nativamente pensate in maniera diversa. Quello che è stato tipicamente portato avanti è un approccio alla soluzione del tutto analogo a quello seguito per anni dai sistemi di Data warehousing: caricamento batch di dati (prevalentemente transazionali), processamento via strumenti di ETL, metamodellazione e presentazione all’utente finale per la visualizzazione.
Questa modalità ha relegato in certi contesti i Data lake a mere sorgenti informative più potenti e veloci che potessero quindi supportare la manipolazione dei dati a volumi e a livelli di dettaglio che tecnologie classiche non sono in grado di sostenere. In alcuni casi vengono utilizzati quindi come “ponte” per lavorare più rapidamente determinati set di dati e riscriverli su database relazionali in forma aggregata.
Il giusto approccio invece, è quello di strutturare i Data lake by design per accogliere dati sia strutturati che non strutturati, in modalità non solo schedulata batch, ma anche in realtime streaming, da poter essere acceduti in loco (non estratti tutte le volte che sono necessari, per essere trasferiti verso altri sistemi) favorendo la Data discovery per una successiva modellazione ed esposizione ad altre applicazioni/processi/strumenti aziendali, agilmente.
Big question vs. small question
Sfruttare al meglio le potenzialità dei Data lake in azienda dipende anche da quelli che sono i problemi che ci si aspetta di risolvere con il loro utilizzo. È ampio l’utilizzo di queste tecnologie per rispondere in maniera più efficiente rispetto a Data warehouse a domande con un perimetro ben definito, small question appunto, come determinare le vendite in un certo orizzonte temporale oppure quelli che sono le motivazioni che maggiormente causano guasti alla catena produttiva.
Tuttavia il potenziale che questi strumenti hanno, e che dovrebbe essere sfruttato, è quello di poter aiutare a rispondere a domande con un contesto più ampio che possono portare maggior valore in azienda, come ad esempio la probabilità di churn da parte di un cliente e la sua storia oppure le azioni precauzionali che si dovrebbero mettere in campo per evitare rotture in macchinari di produzione (la predictive maintenance). Parte da noi e dalle big question alle quali cerchiamo risposta che viene determinata la vera utilità dei Data lake.
Data democratization
Inizialmente professati come aree esclusive per lo sviluppo da parte di professionisti altamente qualificati come i Data scientists, i Data lake si sono dimostrati più “aperti” di quanto si pensasse inizialmente. Il 33% delle aziende intervistate dichiara che il proprio Data lake è acceduto da più di 250 utenti (che presumibilmente non saranno tutti con competenze di analytics o di programmazione), mentre si stima che il 50% di questi utilizzino strumenti di BI tradizionali per accedere al dato, seguito da accessi via SQL e Python.
Questo indica che in realtà i Data lake vanno a integrare e ad arricchire il panorama informativo degli esistenti Business Analyst e non sono una black box per i soli esperti: favorire la giusta documentazione all’accesso, senza colli di bottiglia tecnici e promuovere la Data Democratization anche per questi strumenti, è più che mai fondamentale. Va da sé che, essendo elevata la presenza di dati grezzi ad alta granularità, figure più tecniche saranno quelle che avranno nel Data lake il maggior peso di utilizzo.
Data lake e security
Legato al punto precedente, essendo una struttura differente da quelle solitamente già presenti in azienda, lo sviluppo di un Data lake dovrà essere accompagnato da una dedicata gestione in termini di performance e security. In diversi casi i Data lake sono stati visti come il porto franco sul quale far atterrare i dati più disparati senza che realmente si sapesse dove andare a prendere una certa informazione e cosa questa informazione significasse.
Come per i sistemi legacy, anche per i Data lake introdotti più di recente, la questione relativa all gestione della governance per il suo accesso e la gestione delle policy aziendali, è stato trattato spesso e volentieri come tema a latere e non come vero e proprio pillar su cui basare la sua costruzione.
Anche in questo contesto, la governance è cruciale per poter valorizzare al meglio il ruolo del Data lake nel complessivo panorama dei dati aziendali, insieme alle altre sorgenti informative.
Conclusioni
Raccogliere tutti i dati in un unico punto di ingresso non è sempre la risposta migliore per ottenere il massimo dalle soluzioni data-centriche se questo non segue la strategia aziendale, non fornisce un adeguato e diffuso accesso e non risponde alle domande giuste. I Data lake non fanno eccezione a questi principi.
Anche nel contesto dei Data lake, può portare beneficio seguire un approccio strategico e incrementale, procedendo per integrazioni light iniziando con MVP (minimum viable products) e piccoli team dedicati su perimetri dati definiti, un’architettura ben strutturata che non punti a ricalcare quanto fatto per i Data warehouse e policy di accesso chiare, creando quelli che vengono anche chiamati Data ponds, andando quindi a integrare mano a mano, sfruttando le peculiarità di scalabilità e condivisione.
La questione fondamentale che bisogna comprendere in primo luogo è che i Data lake sono un ulteriore componente nella complessa panoramica dell’Enterprise Data Management e quindi, anche se ci sono stati facili entusiasmi soprattutto nei primi anni, è il momento di iniziare a considerarli come una componente necessaria ma non sufficiente all’interno di una efficace Data strategy, con tutti i compiti, le policy e le azioni connesse. Altrimenti non saranno altro che l’ennesimo silos da cui andare a recuperare una piccola porzione di dati di interesse.














