Il data mining si definisce come l’estrazione complessa di informazioni implicite, precedentemente sconosciute e potenzialmente utili dai dati e l’esplorazione e l’analisi, per mezzo di sistemi automatici e semiautomatici, di grandi quantità di dati al fine di scoprire pattern significativi.
Sebbene siano fortemente interrelati fra loro, il termine big si distingue formalmente dal termine data mining, con il quale si indica il processo computazionale di scoperta di pattern in grandi data set utilizzando metodi di machine learning, intelligenza artificiale, statistica e basi di dati.
A parte la fase di analisi vera e propria, il data mining copre aspetti di gestione del dato e pre-processing, modellazione, identificazione di metriche di interesse, visualizzazione.
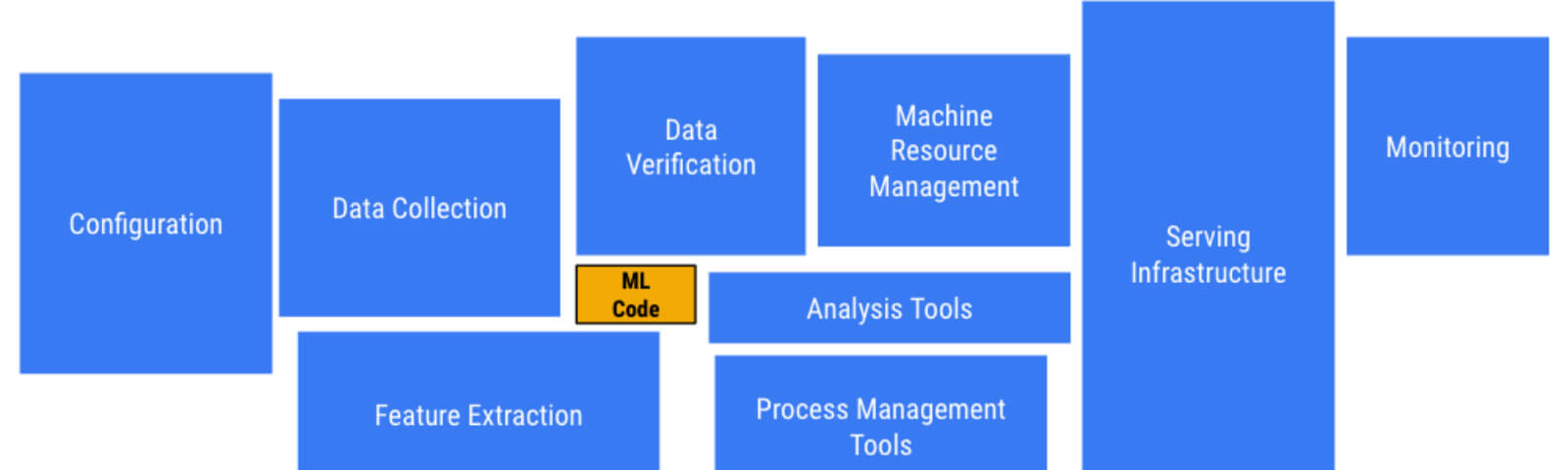
Il ruolo del machine learning in un progetto reale di data mining è reso bene dall’immagine sotto, che elenca le attività necessarie. Ai rettangoli più grandi corrispondono le attività a cui è dedicato più tempo.
Indice degli argomenti
Cos’è il data mining?
Il data mining è un processo che utilizza sofisticati algoritmi matematici per estrarre dati utili da ampie banche dati.
Le aziende, attraverso il software di data mining, possono cercare tra i dati grezzi raccolti, le informazioni utili per il proprio business come: sviluppare strategie di marketing più efficaci,sapere di più sui propri clienti, aumentare le vendite e ridurre i costi.
Perché fare data mining?
I motivi per cui si rende necessario utilizzare sistemi di data mining sono molteplici. Innanzitutto, la quantità di dati memorizzata su supporti informatici è in continuo aumento: pagine web, sistemi di ecommerce, dati relativi ad acquisti e scontrini fiscali, transazioni bancarie relative a carte di credito.
Secondariamente va notato che l’hardware diventa sempre più potente e meno costoso. Dal lato delle aziende, la pressione competitiva è in continua crescita e la risorsa informazione è un bene prezioso per superare la concorrenza.
Anche in campo scientifico, i dati prodotti e memorizzati crescono a grande velocità (GB/ora) e provengono anche da sensori posti su satelliti, telescopi, microarray che generano espressioni genetiche, simulazioni scientifiche che ne producono a terabyte.
Le tecniche tradizionali sono inapplicabili alle masse di dati grezzi; il data mining, invece, può aiutare gli scienziati a classificare e segmentare i dati e formulare ipotesi.
Altri motivi per cui si rende necessario l’utilizzo del data mining sono che molte delle informazioni presenti sui dati non sono direttamente evidenti; le analisi guidate dagli uomini possono richiedere settimane per scoprire informazioni utili e una larga parte dei dati non è di fatto mai analizzata.
Cos’è un pattern e i vari tipi
Un pattern è una rappresentazione sintetica e ricca di semantica di un insieme di dati; esprime in genere un modello ricorrente nei dati, ma può esprimere anche un modello eccezionale.
Un pattern deve essere:
- valido sui dati con un certo grado di confidenza
- comprensibile dal punto di vista sintattico e semantico, affinché l’utente lo possa interpretare
- precedentemente sconosciuto e potenzialmente utile, affinché l’utente possa intraprendere azioni di conseguenza.
Tipi di pattern
- Regole associative: consentono di determinare le regole di implicazione logica presenti nella base di dati, quindi di individuare i gruppi di affinità tra oggetti.
- Classificatori: consentono di derivare un modello per la classificazione di dati secondo un insieme di classi assegnate e priori.
- Alberi decisionali: sono particolari classificatori che permettono di identificare, in ordine di importanza, le cause che portano al verificarsi di un evento.
- Clustering: raggruppa gli elementi di un insieme, a seconda delle loro caratteristiche, in classi non assegnate a priori.
- Serie temporali: permettono l’individuazione di pattern ricorrenti o atipici in sequenze di dati complesse.

Esempi e tecniche di data mining
Questa disciplina trae ispirazione dalle aree di machine learning/intelligenza artificiale, pattern recognition, statistica e basi di dati. Il data mining nasce per sostituire le tradizionali tecniche di analisi, che risultano inidonee per vari motivi:
- quantità di dati
- elevata dimensionalità dei dati
- eterogeneità dei dati.
Esempi di data mining
Un esempio di data mining è quando effettuiamo ricerche sui cognomi più comuni in certe regioni o raggruppiamo i documenti restituiti da un motore di ricerca in base a informazioni di contesto (ad es. “foresta pluviale amazzonica”).
Vediamo ora cosa non è il data mining. Ad esempio, cercare un numero nell’elenco telefonico o interrogare un motore di ricerca per cercare informazioni, non è fare data mining.
Tecniche del data mining
Le attività tipiche del data mining sono quelle dei sistemi di predizione: utilizzare alcune variabili per predire il valore incognito o futuro di altre variabili; e dei sistemi di descrizione: trovare pattern interpretabili dall’uomo che descrivano i dati.
Attività del data mining sono:
- classificazione (predittiva),
- clustering (descrittiva),
- ricerca di regole associative (descrittiva),
- ricerca di pattern sequenziali (descrittiva),
- regressione (predittiva),
- individuazione di deviazioni (predittiva).
1) Classificazione predittiva del data mining
Definizione: data una collezione di record (training set), ogni record è composto da un insieme di attributi di cui uno esprime la classe di appartenenza del record. Trova un modello per l’attributo di classe che esprima il valore dell’attributo in funzione dei valori degli altri attributi
Obiettivo: record non noti devono essere assegnati a una classe nel modo più accurato possibile. Viene utilizzato un test set per determinare l’accuratezza del modello. Normalmente il dataset fornito è suddiviso in training set e test set. Il primo è utilizzato per costruire il modello, il secondo per validarlo.
Primo esempio di applicazione del data mining: Direct marketing
Obiettivo: ridurre il costo della pubblicità via posta definendo l’insieme dei clienti che, con maggiore probabilità, compreranno un nuovo prodotto di telefonia
Approccio: utilizza i dati raccolti per il lancio di prodotti similari. Conosciamo quali clienti hanno deciso di comprare e quali no. Questa informazione (compra, non compra) rappresenta l’attributo di classificazione. Raccogli tutte le informazioni possibili legate ai singoli compratori: demografiche, stile di vita, precedenti rapporti con l’azienda; attività lavorativa svolta, reddito, sesso, età, ecc. Utilizza queste informazioni come attributi di input per addestrare un modello di classificazione.
Secondo esempio di applicazione: individuazione di frodi
Obiettivo: predire l’utilizzo fraudolento delle carte di credito
Approccio: utilizza le precedenti transazioni e le informazioni sui loro possessori come attributi (quando compra l’utente, cosa compra, paga con ritardo, ecc.). Etichetta le precedenti transazioni come fraudolente o lecite. Questa informazione rappresenta l’attributo di classificazione. Costruisci un modello per le due classi di transazioni. Utilizza il modello per individuare comportamenti fraudolenti delle prossime transazioni relative a una specifica carta di credito.
2) Clustering del data mining
Definizione: dato un insieme di punti, ognuno caratterizzato da un insieme di attributi, e avendo a disposizione una misura di similarità tra i punti, trovare i sottoinsiemi di punti tali che: i punti appartenti a un sottoinsieme sono più simili fra loro rispetto a quelli appartenenti ad altri cluster.
Misure di similarità: la distanza euclidea è applicabile se gli attributi dei punti assumono valori continui. Sono possibili molte altre misure che dipendono dal problema in esame.
Esempio di applicazione del data mining: segmentazione del mercato
Obiettivo: suddividere i clienti in sottoinsiemi distinti da utilizzare come target di specifiche attività di marketing
Approccio: raccogliere informazioni sui clienti legate allo stile di vita e alla collocazione geografica. Trovare cluster di clienti simili. Misurare la qualità dei cluster verificando se il pattern di acquisto dei clienti appartenenti allo stesso cluster è più simile di quello di clienti appartenenti a cluster simili
3) Regole associative del data mining
Definizione: dato un insieme di record, ognuno composto da più elementi appartenenti a una collezione data, produce delle regole di dipendenza che predicono l’occorrenza di uno degli elementi in presenza di occorrenze degli altri.
Esempio di applicazione del data mining: disposizione della merce
Obiettivo: identificare i prodotti comprati assieme da un numero sufficientemente elevato di clienti
Approccio: utilizza i dati provenienti dagli scontrini fiscali per individuare le dipendenze tra i prodotti. Una classica regola associativa è: se un cliente compra pannolini e latte, allora molto probabilmente comprerà birra. Lo scaffale delle birre verrà posizionato vicino a quello dei pannolini per bambini.
4) Regressione del data mining
Definizione: predire il valore di una variabile a valori comuni sulla base di valori di altre variabili assumendo un modello di dipendenza lineare/non lineare. Un problema ampiamente studiato in statistica e nell’ambito delle reti neurali.
Esempi di applicazione del data mining: predire il fatturato di vendita di un nuovo prodotto sulla base degli investimenti in pubblicità – predire la velocità del vento in funzione della temperatura, umidità, pressione atmosferica – predizione dell’andamento del mercato azionario.
In conclusione, le caratteristiche del data mining sono: la scalabilità, la multidimensionalità del data set, la complessità ed eterogeneità dei dati, la qualità dei dati, la proprietà dei dati, il mantenimento della privacy, il processing in real time.
Qual è la differenza tra data mining e machine learning
Molte persone confondono il data mining con il machine learning. Sebbene ci siano alcune somiglianze, i due concetti differiscono molto tra loro.
Vediamo nello specifico quali sono le differenze tra data mining e machine learning:
- Il data mining è un processo manuale che richiede l’intervento dell’uomo. Il processo del machine learning, una volta stabilite le regole, è automatico e senza intervento umano.
- Nel data mining le regole sono sconosciute all’inizio del processo mentre al machine learning vengono fornite per comprende i dati e apprendere.
- Il data mining viene usato su una banca dati esistente per trovare modelli. Il machine learning viene utilizzato su una banca dati in formazione che addestra il computer a leggere i dati e fare delle previsioni.
Nonostante le nette differenze tra i due, poiché le aziende diventano sempre più predittive, potremo assistere in futuro ad una sovrapposizione tra machine learning e data mining.
Data mining: l’approccio metodologico Crisp-DM
Un progetto di data mining richiede un approccio strutturato in cui la scelta del miglior algoritmo è solo uno dei fattori di successo. La metodologia Crisp-DM è una delle proposte maggiormente strutturate per definire i passi fondamentali di un progetto di data mining
Le sei fasi del ciclo di vita non sono strettamente sequenziali. È spesso necessario tornare su attività già svolte.
- comprensione del dominio applicativo: capire gli obiettivi del profitto del punto di vista dell’utente, tradurre il problema dell’utente in un problema di data mining e definire un primo piano di progetto
- comprensione dei dati: raccolta preliminare dei dati finalizzata a identificare problemi di qualità e a svolgere analisi preliminari che permettano di identificare le caratteristiche salienti
- preparazione dei dati: comprende tutte le attività necessarie a creare il data set finale: selezione di attributi e record, trasformazione e pulizia dei dati
- creazione del modello: diverse tecniche di data mining sono applicate al data set anche con parametri diversi al fine di individuare quella che permette di costruire il modello più accurato
- valutazione del modello e dei risultati: il modello o i modelli ottenuti dalla fase precedente sono analizzati al fine di verificare che siano sufficientemente precisi e robusti da rispondere adeguatamente agli obiettivi dell’utente
- deployment: il modello costruito e la conoscenza acquisita devono essere messi a disposizione degli utenti. Questa fase può semplicemente comportare la creazione di un report oppure può richiedere di implementare un sistema di data mining controllabile direttamente dall’utente.

Articolo originariamente pubblicato il 13 Ott 2022
















