Indice degli argomenti
Cos’è la data science
La data science è la scienza che estrae valore dai dati. Si basa quindi su metodi scientifici, principalmente statistici, e tecniche di analisi per trasformare un dato in una informazione utile per un determinato contesto e determinati obiettivi.
Più precisamente, l’oggetto della data science sono i big data: dati dal volume così grande da richiedere tecniche e metodi specifici per poter essere analizzati in un tempo ragionevole.
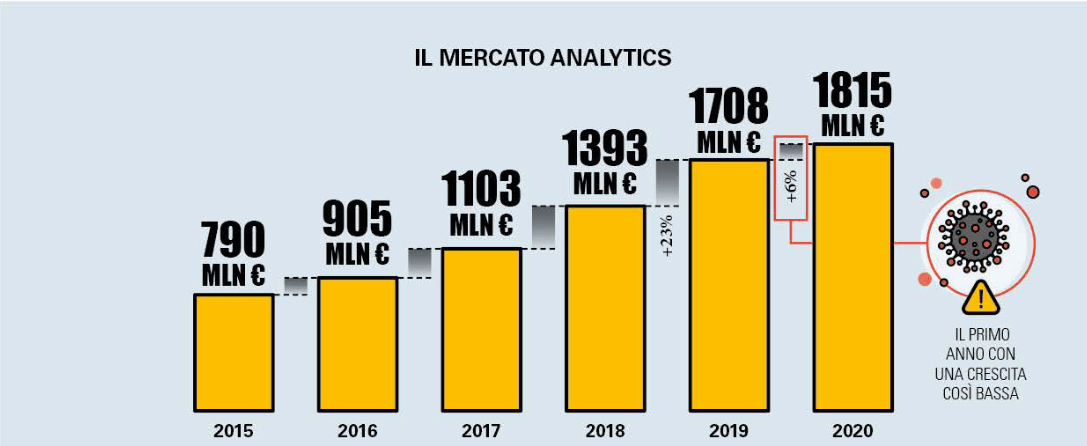
I big data vengono generati e scambiati attraverso Internet da dispositivi connessi e relativi software (Internet of Things): il mercato analytics, nonostante il rallentamento dovuto alla pandemia, nel 2020 è cresciuto solo in Italia del 6%, raggiungendo un valore di 1815 milioni di euro.
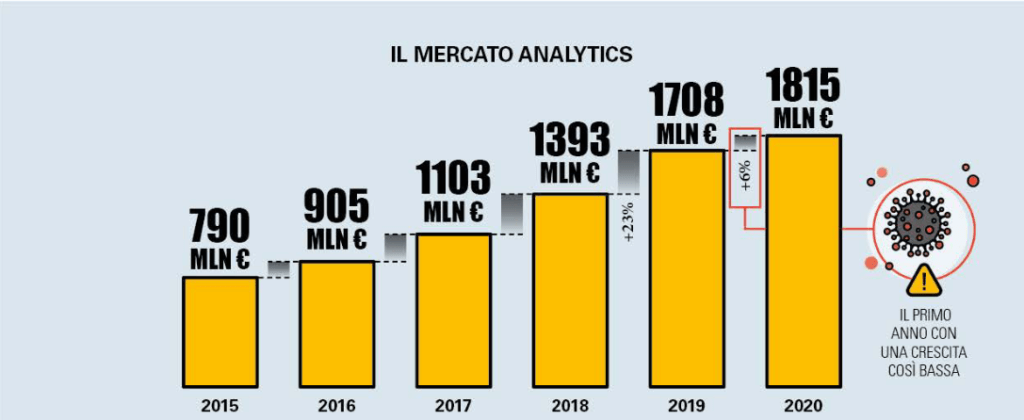
Infografica- Fonte: Osservatorio Big Data & Business Analytics – Politecnico di Milano
Il termine data science è stato coniato nel 1974 dall’informatico danese Peter Naur, in relazione alla possibilità di gestire e manipolare dati: quasi trent’anni dopo, nel 2000, il ricercatore di statistica ai Bell Laboratories William Cleveland ha sottoposto il paper “Data Science: an action plan for expanding the technical areas of the field of statistics” all’International Statistics Review. Nel paper, pubblicato l’anno successivo, ha delineato i sei campi di competenza della data science intesa come disciplina a sé stante: i fondamenti teorici, le indagini multidisciplinari, la costruzione di modelli statistici, il calcolo e l’elaborazione dei dati, la valutazione degli strumenti, la formazione.
Nello stesso anno, nel febbraio 2001, Doug Laney, allora vice-presidente di Meta Group, nel paper “3D Data Management: Controlling Data Volume, Velocity and Variety”, ha caratterizzato i big data con 3V: Volume, Velocità e Varietà.
Volume, di generazione e crescita: più del 50% l’anno. Velocità, di generazione e analisi in tempo reale. Varietà, di tipologie, da fonti eterogenee come smartphone, sensori, social network, dispositivi IoT, e di formati, sia strutturati, ovvero già organizzati in tabelle, sia non strutturati.
A queste 3 V si sono presto aggiunte la Veridicità, ovvero l’affidabilità e l’integrità, e il Valore, la conoscenza che i dati permettono di ampliare in relazione a un contesto.
Secondo l’Osservatorio Big Data & Business Analytics del Politecnico di Milano, in Italia nel 2020 su un campione di 137 grandi aziende, il 96% ha avuto in atto iniziative per valorizzare i dati e il 42% è stato definibile come maturo in ambito delle Advanced Analytics, le metodologie di analisi ed elaborazione che comprendono la simulazione e le risposte su scenari futuri nonché l’automatizzazione di processi. Per quanto riguarda invece le PMI, su 500 piccole e medie imprese italiane, nel 2020 una su due ha investito in Analytics e il 62% ha in corso attività di analisi di dati.
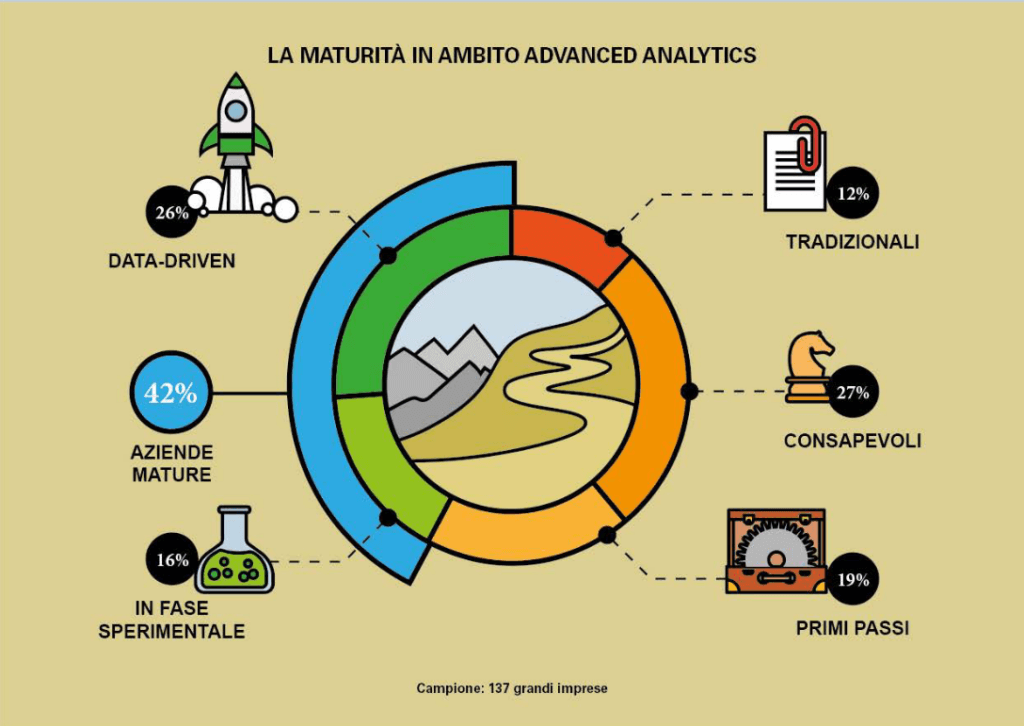
Infografica: Osservatorio Big Data & Business Analytics – Politecnico di Milano
Che differenza c’è tra data science, AI e machine learning
Data science, AI e Machine Learning vengono spesso usati come sinonimi. In realtà non lo sono, pur essendo tre termini in relazione tra loro.
L’AI – Artificial Intelligence, o, in italiano, intelligenza artificiale, è quel campo dell’informatica che ha come obiettivo costruire “macchine” che imitino il, o assomiglino al, comportamento umano: che comprendano quindi sia la sfera del “pensare” che quella dell’“agire”.
Data Science e Machine Learning sono due sottoinsiemi dell’intelligenza artificiale.
Il “Machine Learning” è, letteralmente, l’apprendimento (automatico) della “macchina”: il sistema informatico apprende dai dati a riconoscere schemi ricorrenti, o pattern, attraverso algoritmi artificiali, supervisionati o meno. In entrambi i casi, il sistema viene “allenato” attraverso un dataset diviso in due parti, il set di addestramento e il set di test vero e proprio: la macchina impara con il passar del tempo a riconoscere le correlazioni nel set di test a partire da quelle mostrate prima all’interno del set di addestramento. Ri-allenando il modello con quantità maggiori di dati, l’apprendimento diventa sempre più accurato.
Tra i principali algoritmi supervisionati ci sono le reti neurali artificiali, modelli di calcolo matematico che funzionano per connessioni, come nella rete neurale naturale. Connessioni che cambiano di peso a seconda delle informazioni mostrate durante la fase di apprendimento. Tra i metodi di apprendimento non supervisionato, più comune, troviamo il Clustering e il Data Mining: nel primo caso, l’obiettivo è trovare i Cluster, gruppi con caratteristiche simili, nei dati in ingresso; nel secondo, relazioni tra i dati non ancora conosciute.
La Data Science è la disciplina scientifica di costruzione di modelli statistici e di tecniche di analisi che servono a trarre valore dai dati. È meno tecnica e più ampia del machine learning, occupandosi anche del “cosa” e non solo del “come”. Viene definita come un sottoinsieme dell’intelligenza artificiale perché i risultati della data science concorrono a costruire agenti intelligenti.
Quali sono i vantaggi della data science
La data science consente di generare valore dai dati prodotti dai dispositivi dentro e fuori l’azienda.
Il primo vantaggio è una migliore gestione degli asset, ovvero delle risorse aziendali, non solo in termini economici: la data science e i suoi software di analisi ed elaborazione aiutano a monitorare in tempo reale i processi, ridurre gli sprechi, delineare scenari che collaborano a definire e attuare in modo efficace la strategia di impresa. Analizzare i dati significa valutare i rischi, studiare il ciclo di vita di beni e strumenti, calcolare preventivamente gli interventi di manutenzione, tracciare le scadenze.
Proprio una manutenzione più efficace è il secondo vantaggio che deriva dalla data science: il monitoraggio in tempo reale di attrezzature e impianti consente di intervenire prima che si verifichi il guasto, la cosiddetta manutenzione predittiva o Condition Based Maintenance. Tutte le azioni di manutenzione vengono tracciate e archiviate in automatico dai software di elaborazione e rese accessibili su un’unica piattaforma: dagli ordini di lavoro alle richieste di intervento fino alla rendicontazione dei costi e la tracciatura dei fermi macchina.
La data science consente inoltre di ottimizzare il controllo di produzione: dall’ingresso delle materie prime al prodotto finito, tutti i processi possono essere tracciati, monitorati e verificati grazie ai dati prodotti dall’inventario, dalla gestione delle componenti, dal personale, dall’attività di magazzino e stoccaggio fino al ciclo produttivo vero e proprio, quindi modi e tempi dei fermi macchina, la quantità dei pezzi prodotti, le interruzioni di produzione, i tempi di manutenzione, di consegna e preparazione spedizioni. I software di elaborazione dati controllano in tempo reale quantità e consumi delle materie prime, riducendo gli stock inutilizzati; analizzano i dati dei carichi di lavoro, eliminando i sovraccarichi; aiutano a gestire l’imprevisto in tempo reale, senza fermare la produzione; rendono il processo produttivo completamente tracciabile; migliorano il controllo qualità diminuendo gli errori di fabbricazione e i costi di rilavorazione; riducono il consumo energetico.
La data science serve inoltre ad aumentare la sicurezza negli impianti: ne sono esempi i sistemi di rilevamento ambientale che monitorano la qualità dell’aria ed eventuali fughe di gas; i sistemi di videosorveglianza industriale che sorvegliano gli accessi; i sistemi di sicurezza anticollisione che riducono il rischio di incidenti nelle aree di lavoro; i dispositivi “uomo a terra” che segnalano all’operatore e al responsabile della sicurezza la possibile “caduta” in condizioni di lavoro isolato. Tutti sistemi che si basano su software che elaborano in tempo reale i dati provenienti da sensori per aiutare a prendere la migliore decisione possibile in relazione al contesto. Fondata sui dati è la cybersecurity e i relativi Cybersecurity Management System, i sistemi integrati di gestione della sicurezza informatica.
Non ultima, la data science può contribuire a migliorare l’esperienza d’acquisto, attraverso il monitoraggio del comportamento del cliente che consente di implementare la personalizzazione dell’offerta. Videocamere negli store, reporting dei POS, analisi delle recensioni, forniscono dati utili per capire meglio le tendenze di vendita, la percezione dell’offerta, i margini di profitto attesi e realizzati.
In quali ambiti viene utilizzata?
Secondo quanto riportato dall’Osservatorio Big Data &Business Analytics del Politecnico di Milano, nel 2020 in Italia le banche sono state il primo settore per quota di mercato analytics (28%), seguite da manifattura (24%), telco e media (14%), servizi (8%), Gdo e retail (7,5%), assicurazioni (7%), utility (6.5%), PA e sanità (5%)
La ricerca evidenzia come durante la pandemia la “fame di dati” sia aumentata e i team di data science abbiano ottenuto maggiore visibilità interna, in direzione di un cambiamento culturale in ottica data-driven.
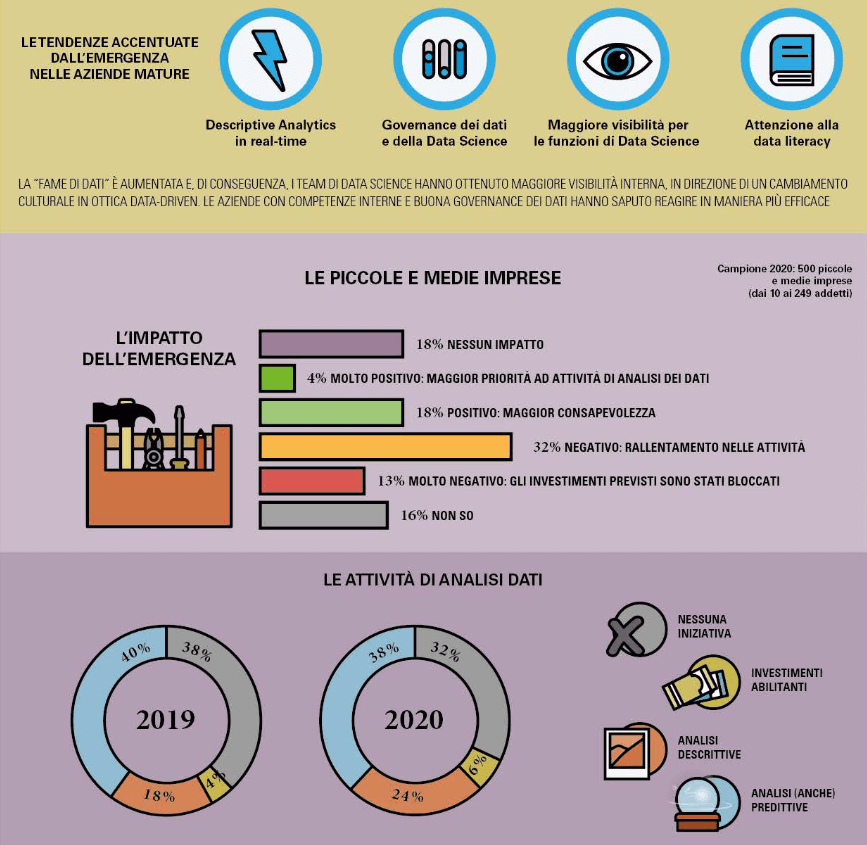
Infografica: Osservatorio Big Data & Business Analytics – Politecnico di Milano
Ma come viene utilizzata la data science nei diversi settori?
Le banche usano la data science per profilare meglio le abitudini dei clienti e ridurre al minimo rischi e frodi, nel rispetto delle normative nazionali e internazionali: la data science serve a modellizzare e misurare il rischio di credito e di controparte, ridurre i tempi dei cicli di stress test, migliorare la trasparenza e la verificabilità del flusso di lavoro con l’automazione, prendere decisioni migliori ottimizzando le performance durante l’intero ciclo di vita del servizio, creare report normativi e gestionali accurati e on-demand.
L’industria manifatturiera si serve della data science per ottimizzare la produzione, aumentando la qualità e riducendo gli sprechi. La data science aiuta ad eliminare i silos di dati e incrociare quelli di processo, di prodotto e del cliente; a effettuare un’analisi avanzata che identifica i problemi prima che si verifichino; a raggiungere un controllo avanzato del processo produttivo, monitorandolo in tempo reale; ad analizzare le cause profonde dei problemi di produzione; ad avere una visione sistemica delle operazioni; a ridurre i costi di manutenzione e massimizzare l’efficacia delle attrezzature; ad ottimizzare la logistica.
Il retail utilizza la data science per approfondire la relazione con il cliente e migliorare la sua customer experience: prevederne la domanda, comprenderne il percorso d’acquisto, identificare le opportunità per migliorare le prestazioni, ottimizzare il merchandising. L’analisi dei dati esplicita le dimensioni reali della domanda e lo storico delle vendite, così da raffinarne la previsione e consigliare le migliori configurazioni di confezioni per la logistica e la distribuzione. La data science aiuta anche nella pianificazione di dove localizzare le merci: a creare assortimenti rilevanti, ottimizzare le scorte, utilizzare l’analisi dell’area commerciale per determinare il posizionamento nello store e online, prezzo compreso.
Il settore sanitario può servirsi della data science per scoprire le informazioni nascoste capaci di migliorare l’assistenza ai pazienti: analizzare i dati clinici e operativi strutturati e non, trasformare le intuizioni in conoscenze basate sull’evidenza, determinare il trattamento ottimale, comprendere i fattori che influenzano le riammissioni in ospedale. L’analisi e la condivisione dei dati aiutano ad evitare errori farmacologici, a studiare e identificare i pazienti a rischio, ad ottimizzare la pianificazione della dimissione, ad avere una visione sistemica dei servizi offerti e del loro impatto sul territorio e misurarne l’efficacia, a pianificare strategia di assistenza e cura ottimizzate.
Come sta trasformando le aziende?
La data science sta trasformando le aziende in molti settori: di seguito qualche esempio 2019-2020 raccolto dall’Osservatorio Big Data & Business Analytics del Politecnico di Milano.
Nel settore energia-servizi, CPL Concordia, società cooperativa che si occupa di cogenerazione, energy management e servizi per l’efficientamento energetico degli edifici, ha creato e strutturato un data-lake, un ambiente di deposito dei dati, unico per tutte le informazioni a disposizione dell’azienda. Un database su cui costruire un cruscotto dedicato al monitoraggio energetico con analisi predittive per la riduzione dei consumi e un migliore servizio ai clienti.
Nel settore telco, Vodafone Automotive, società del Gruppo Vodafone che fornisce piattaforme tecnologiche connesse per la mobilità, ha risposto all’esigenza di gestire i big data delle black box montate sui veicoli, con una nuova architettura di raccolta, analisi, elaborazione e archiviazione dei dati, anche per supportare le realtà assicurative nel processo di valutazione del rischio per la stipula delle polizze. La nuova architettura è stata resa disponibile on-premises con un cluster di server di backup nel data center gemello destinato alla disaster recovery.
Nel settore manifatturiero, Tenaris, tra i maggiori produttori e fornitori globali di tubi in acciaio e servizi per l’industria energetica, ha introdotto un tool di data visualization in grado di rispondere alle diverse esigenze di visualizzazione interattiva e analisi esplorativa dei dati. Lo strumento viene utilizzato, ad esempio, al momento dell’acquisto di un prodotto: le analisi dei dati controllano se il prodotto, o simile, sia già presente in qualche altro impianto del gruppo e in questo caso suggeriscono di effettuare un acquisto inter-company. Un altro esempio è l’automonitoraggio compiuto dagli esperti dei vari processi industriali.
Nel settore beni durevoli, la Whirlpool Corporation, multinazionale statunitense produttrice di elettrodomestici, ha sviluppato internamente un motore di demand forecasting (previsione della domanda) costruito sulle caratteristiche di ciascun mercato locale: questo ha consentito di omogeneizzare le attività a livello regionale, con un maggior controllo sulla pianificazione della domanda e un maggiore efficientamento dei costi.
Nel settore vitivinicolo, la Masi Agricola, produttrice di Amarone e altri vini di pregio della Valpolicella, in provincia di Verona, ha avviato un progetto di monitoraggio e analisi dei dati web e social a partire dalle immagini e dai testi condivisi online sulle tipologie di vini prodotti nel territorio: ciò ha portato ad una maggiore efficacia delle campagne marketing e un miglioramento della reputazione dell’azienda.
















