Per una serie di problematiche fondamentali, l’interesse verso lo sviluppo di procedure in grado di generare dati sintetici si sta facendo via via sempre più forte nel mondo dell’industria 4.0: oltre alle ben note difficoltà legate al rispetto della privacy, vi è la necessità da parte di strutture algoritmiche complesse (come, ad esempio, le reti neurali) di dover approvvigionarsi di un grande quantitativo di dati. Non solo: i dati a disposizione dovrebbero riportare una caratteristica determinante per l’ottenimento di risultati realistici, ovvero un’accurata annotazione (altresì detto labeling). Purtroppo, per tutta una serie di svariati motivi, non sempre è possibile poter soddisfare tali requisiti.
Nel corso degli ultimi anni sono stati sviluppati molteplici metodi in grado di poter generare efficacemente dei dataset sintetici, aggiungendo quindi un ulteriore livello procedurale all’interno di una pipeline di apprendimento: ciò permette di ottenere dati molto verosimili, andando a tagliare ulteriori costi derivanti dalla raccolta e annotazione di questi ultimi.
Nell’ideare algoritmi di Deep Learning in grado (ad esempio) di permettere l’automazione di robot all’interno della propria fabbrica o di fornire assistenza quando si è alla guida di un’automobile, è fondamentale poter attingere a tantissimi dati visivi (come immagini e video), annotati con dovizia di particolari. L’atto di andare ad evidenziare specifiche regioni riportate all’interno di foto e video viene denominato segmentazione: la precisione nel delineare queste aree può fare la differenza nell’avere o meno un algoritmo in grado di interagire efficacemente con l’ambiente circostante. Solitamente questa operazione viene effettuata da annotatori umani, risultando essere un ulteriore costo da tenere in considerazione, oltre alla scarsa precisione delle annotazioni. Altro fatto da considerare sono le restrizioni in termini di privacy che possono emergere nel caso in cui vi sia la necessità di avere a disposizione categorie di dati che agli occhi della legislazione vigente sono giudicati come “sensibili”. Tutte queste difficoltà possono essere superate, grazie a nuove metodologie in grado di generare dataset sintetici, ovvero insiemi di dati creati prendendo spunto da dei dati reali. Ciò è possibile grazie a tecniche che apprendono ciò che “contraddistingue” i dati reali: tra le architetture più celebri in letteratura in questo senso vi sono le GAN (Generative Adversarial Neural Network), in grado di plasmare nuovi dati grazie all’addestramento di due strutture, ossia un generatore G e un discriminatore D. I nuovi dati sintetici possono essere resi ancor più realistici affiancando tecniche di ibridizzazione. Inoltre, i moderni game-engine possono concorrere alla realizzazione di scenari virtuali, utili per poter addestrare efficacemente dei robot all’interno di una catena di produzione automatizzata.
Indice degli argomenti
1 – Limitazione dei dataset attualmente esistenti
Come è possibile poter generare delle annotazioni il più precise possibili, nel caso in cui si abbia a che fare con un imponente quantitativo di dati (come 100.000 immagini)? Sebbene per alcune funzioni (es.: classificazione di immagini) siano già disponibili dei dataset più che soddisfacenti (ImageNet), in altre situazioni si potrebbe avere a che fare con dati che peccano in mancanza di annotazioni precise (Fig. 1). Questo fenomeno viene definito in letteratura come la maledizione dell’annotazione del dataset (The curse of dataset annotation)[1]. Altri limiti di cui tenere conto sono:
- Valutazione del modello: il solo utilizzo di dati reali potrebbe non risultare sufficiente nel caso in cui si voglia testare la propria architettura “profonda”, nel tentativo di far emergere eventuali falle nel design di quest’ultima. L’utilizzo di dataset sintetici può porre sotto i riflettori qualsivoglia criticità, consentendo la formulazione di ipotesi da sottoporre a dei test tramite la generazione di un “ambiente controllato”[2].
- Alleviamento dei bias: alcuni dataset potrebbero non essere in grado di generalizzare al meglio tutte le possibili casistiche da sottoporre ad un eventuale algoritmo di apprendimento. Il rischio è quello di addestrare una struttura “carente” nei confronti di alcuni dati in input: più in generale, questo tipo di problema viene definito in statistica con il termine bias. Dunque, i dataset sintetici possono aiutare a coprire eventuali falle statistiche presenti all’interno di una raccolta dati reale[2].

- Ottimizzazione dello spazio: se la generazione di dati sintetici risulta migliorare l’algoritmo a cui verranno dati in pasto, sarà possibile poter produrre “sul posto” nuovi dataset, ottimizzando dunque l’utilizzo della memoria[2].
- Risoluzione di problemi legati alla privacy: la produzione di dati sintetici può aiutare a superare eventuali ostacoli legati all’utilizzo di dati sensibili. Per esempio, nel caso in cui si debba avere a che fare con informazioni riguardanti lo stato di salute o la situazione economico-finanziaria di una persona.
2 – Esempi di dataset sintetici
Attualmente i dataset sintetici vengono applicati con successo in due campi: la guida autonoma (autonomous driving, AD) e l’automazione industriale. Per dovere di cronaca, verranno citati due celebri dataset virtuali per l’AD: Virtual Kitti[3] e SYNTHIA[5].
Virtual Kitty nasce con l’idea di mimare l’acquisizione di video e immagini all’interno di uno scenario urbano, esattamente come avveniva nella sua controparte reale, ovvero KITTI[4]: anziché far viaggiare una vera auto con telecamere, scanner 3D e laser, le stesse operazioni di acquisizione vengono compiute in un mondo virtuale all’interno del game-engine di Unity[3]. Tra gli aspetti da non sottovalutare, c’è il fatto che questo tipo di acquisizione rende possibile un’accurata annotazione delle scatole di delimitazione 3D e 2D (3D e 2D bounding box): come il nome suggerisce, si trattano di coordinate spaziali in grado di permettere l’individuazione dell’area occupata da un oggetto all’interno di uno spazio 3D o di un’area a 2 dimensioni. SYNTHIA pone maggiore enfasi sull’annotazione semantica degli oggetti presenti nel mondo virtuale: esso propone 13 classi di labeling, in modo tale da avere a disposizione un gran numero di aree di segmentazione[5]. Anche qui, l’area urbana è stata generata tramite l’utilizzo di Unity[5]. Una delle caratteristiche più interessanti di SYNTHIA risiede nel fatto che tutti gli oggetti 3D sono stati resi scaricabili[5]: di conseguenza, sarà possibile generare nuove aree metropolitane in modo del tutto casuale, utilizzando ogni componente come una singola unità (Figura 2).

3 – Dal sintetico al reale: gli Autoencoder
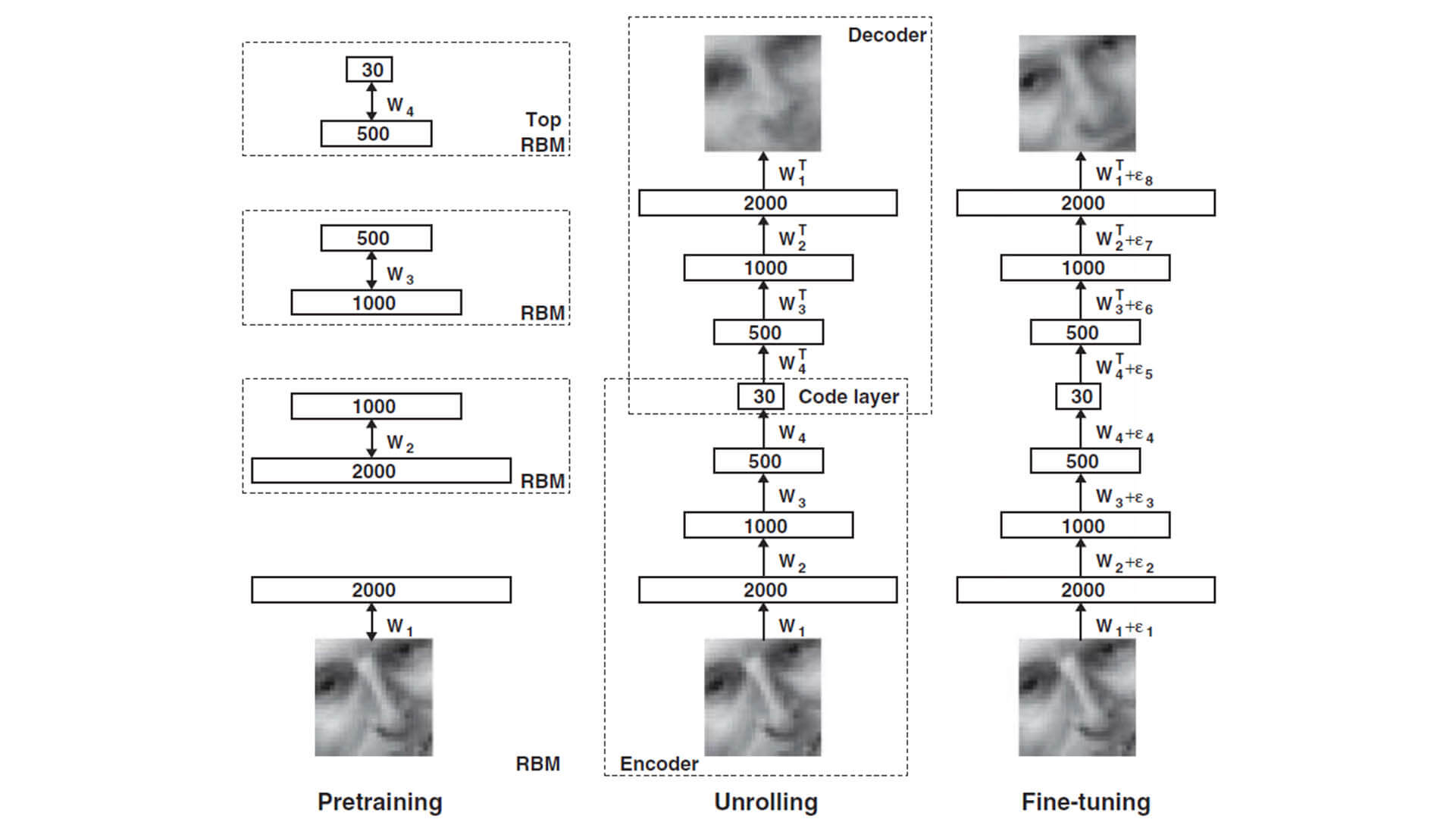
Gli Auto-Encoder furono originariamente introdotti con lo scopo di effettuare una riduzione di dimensionalità delle feature di un dataset in maniera più efficiente rispetto a quanto avviene con tecniche analitiche ben più note, come la PCA[7]. Prendendo spunto da quanto avveniva in una macchina di Boltzmann ristretta (restricted Boltzmann Machine), in cui ogni coppia di layer funge da feature detector in modo tale da acquisire le caratteristiche necessarie per poter delineare delle corrette funzioni di attivazione, i vari strati sono fusi in una sorta di schema “ad imbuto”: in questo modo, si crea una struttura a pila in grado di poter effettuare la corretta riduzione di dimensionalità, mantenendo inalterata le capacità di generalizzazione concessa dall’architettura di Boltzmann. La nuova rete profonda sottosta ad una “funzione di perdita” (Loss Function) che deve fornire una misura qualitativa del dato ricostruito, rispetto al dato originale passato in input.

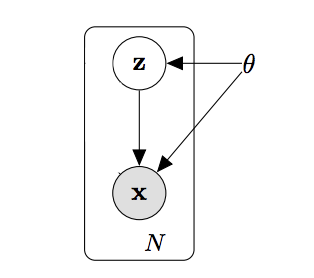
Nella formula, viene riportato il learning rate e la discrepanza che esiste tra il dato originale e quello ricostruito[7]. In sintesi, un autencoder è caratterizzato da due sotto-strutture, un encoder e un decoder, aventi rispettivamente la funzione di ridurre e di ripristinare la dimensionalità del dato. E’ possibile far sì che un auto-encoder sia in grado di astrarre la distribuzione probabilistica che governa il dataset, in modo tale da generare nuovi dati tramite lo spazio latente derivato dall’encoder: ciò è attuabile tramite i Variational Auto-Encoder (VAE), all’interno dei quali l’encoder e il decoder vengono denotati in maniera probabilistica [8]. Stavolta, la discrepanza della ricostruzione viene formulata tramite una divergenza di Kullback-Leibler, tenendo conto delle due distribuzioni:



Utilizzando una struttura profonda, sarà possibile poter creare un campione a partire dalla distribuzione statistica: questa tecnica viene denominata come trucco di re-parametrizzazione (reparametrization trick).
Sebbene gli autoencoder abbiano riportato risultati notevoli per quanto concerne la generazione di dati, la loro inferenza statistica si basa fortemente sui Metodi di Monte-Carlo, che può indurre a una difficile trattazione analitica del problema da affrontare[9].
4 – Imparare a creare: le GAN
Le Generative Adversarial Neural Network (GAN) sono ormai considerate uno standard per la generazione di dati. La logica che governa questa architettura profonda è la seguente: due modelli, G e D, vengono allenati su una porzione di dataset. Il compito di D (ovvero il “Discriminatore”) è quello di stimare la probabilità che un campione provenga dal dataset di training anziché da G (il “Generatore”). Lo scopo di questo “gioco a due” è quello di far sì che G diventi abile a tal punto da ingannare D[9]. La Figura 5 descrive tutto questo: la funzione di G e quella del training set si sovrappongono, facendo sì che D non sia più in grado di discernere l’origine dei dati. In termini statistici, D viene addestrata in maniera tale da massimizzare la probabilità che un dato provenga dal dataset, contrariamente a G che deve minimizzare: questa competizione viene definita come minmax game, e viene descritta dalla seguente funzione:

Il principale punto di forza delle GAN risiede nel fatto che tutti i problemi derivanti dall’utilizzo di catene di Markov e metodo di Monte-Carlo vengono bypassati: il gradiente viene ottenuto tramite l’implementazione dell’algoritmo di retropropagazione (backprop), rimuovendo la necessità di formulare inferenze statistiche[9]. Una volta terminato l’allenamento di questa struttura, si potrà generare dati ex-novo, sfruttando il set probabilistico memorizzato da G.

Degne di menzione sono gli Adversarial Auto-Encoder (AAE), ovvero degli auto-encoder probabilistici che implementano delle GAN in grado di poter effettuare inferenza statistica sulla variabilità dei dati, facendo sì che una distribuzione a posteriori di un vettore di codifica di un auto-encoder combaci con un’arbitraria distribuzione a priori (figura 6)[10]. La misura di verosimiglianza riportata dagli output degli esperimenti fanno presagire che gli AAE possano condurre a ulteriori passi in avanti nella generazione di dati sintetici[10].


5 – Un maggiore realismo: Parallel Imaging e PBR
E’ importante sottolineare il fatto che il solo utilizzo di strutture algoritmiche per modellare nuovi dati rischia di immettere nuovi bias, a causa di alcuni pattern ripetuti che potrebbero compromettere la variabilità del nuovo dataset[2]. Ciò deriva in larga parte dal fatto che l’utilizzo di dati generati artificialmente per applicazioni reali equivale a “spostarsi” da un mondo fittizio a quello reale: prendendo come esempio i dati visivi, è stato notato come sia importante un rendering realistico per attenuare lo shock derivante dalla traslazione di dominio. Questo problema è noto come adattamento di dominio (domain adaptation)[2]. Per porre rimedio a questo tipo di problematiche, nel corso degli anni sono state proposte architetture ibride, in grado di trarre il meglio delle strutture profonde congiuntamente a metodi di manipolazione di dati reali: è il caso di Parallel Imaging, un framework che utilizza approcci guidati di AI assieme ad altri legati all’utilizzo di immagini e video veri. Queste schematizzazioni non escludono l’utilizzo dei vari game-engine, che possono permettere l’aggiunta di un ulteriore fattore di verosimiglianza[12]. In alcuni casi, sono state proposte architetture che contemplano l’utilizzo di tecniche di rendering prese in prestito direttamente dal mondo degli effetti speciali[13], con risultati a dir poco impressionanti (Figura 8).

6 – Esempi di applicazione industriale
Sono molteplici i casi di applicazioni all’interno di fabbriche e industrie dei dati sintetici: ciò non solo permette all’imprenditore di poter accelerare i tempi di adozione di soluzioni maggiormente orientate verso l’automazione, ma anche di poter guadagnare in termini formazione, sia per gli umani che per le macchine. Prendendo spunto dalle architetture viste precedentmente, l’utilizzo dei VAE rende possibile il training delle macchine interamente all’interno di ambienti virtuali[6]: sarà dunque possibile utilizzare lo stesso identico decoder per effettuare un’efficace traslazione di dominio da uno scenario simulato ad uno reale, utilizzando due differenti encoder in grado di poter trattare le due casistiche. Una volta addestrate le varie strutture, sarà possibile utilizzare una Convolutional Neural Network (CNN) per rinvenire le coordinate spaziali con estrema precisione di un qualsiasi oggetto (figura 9)[6].
Nel caso di generazione di dataset, Fallen Things (FAT) è sicuramente meritevole di essere menzionato: sviluppato dalla Nvidia, FAT permette un addestramento ottimale di automi per applicazioni industriali, fornendo una modalità di creazione casuale di scenari altamente realistici. Questa generazione risulta essere abbastanza singolare: una volta delineato il fondale, gli oggetti vengono letteralmente lanciati all’interno dell’ambiente, in modo che la disposizione finale sia guidata dal motore fisico del game-engine Unreal[11]. Completata questa operazione, l’utente avrà a disposizione una dettagliata annotazione dello scenario, utili per l’allenamento di strutture profonde.

7 – Conclusioni
Le reti neurali e più in generale le cosiddette architetture “profonde” stanno causando un cambiamento nelle procedure normalmente utilizzate in alcuni campi inerenti agli algoritmi di apprendimento: anziché sviluppare metodi per risolvere specifici problemi, la ricerca sta puntando verso l’adozione di “paradigmi universali”, in grado di poter mappare uno spazio di input (ovvero, il dato che viene dato in ingresso da un utente) direttamente nel corrispondente spazio di output (il dato prodotto dall’algoritmo)[1]. I dati sintetici non solo accelereranno la ricerca in questa direzione, ma contribuiranno a sopperire a tutte quelle mancanze che possono essere presenti nei dataset reali.
- Pros
- Miglioramento qualitativo dei dataset
- Possibilità di costruzione on-the-fly di dati
- Ottimizzazione nei processi di automazione (basti pensare che attualmente la BMW sta addestrando i suoi co-piloti artificiali per il 95% su piste virtuali)
- Strutture profonde che possono essere ispezionate ed analizzate grazie a dati “controllati”, risultando meno black-box
- Cons
- Rischio di inserire nuovi bias se la generazione non risulti essere abbastanza imprevedibile
- Verosimiglianza necessaria
- Necessità di ibridizzare con il reale per alleviare il domain shift
References
[1] Xie, J. – Kiefel, M. – Sun, M. – Geiger, A.. “Semantic Instance Annotation of Street Scenes by 3D to 2D Label Transfer.” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
[2] Nikolenko, S.. “Synthetic Data for Deep Learning.” ArXiv abs/1909.11512 (2019)
[3] Geiger, A. – Lenz, P. – Stiller, C. – Urtasun, R.. “Vision meets robotics: the KITTI dataset.” The International Journal of Robotics Research. 32. (2013)
[4] Gaidon, A. – Wang, Q. – Cabonn, Y. – Vig, E.. “VirtualWorlds as Proxy for Multi-object Tracking Analysis.” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
[5] Ros, G, – Sellart, L. – Materzynska, J. – Vazquez, D. – Lopez A.. “The SYNTHIA dataset: A large collection of synthetic images for semantic segmentation of urban scenes.” Proceedings of the IEEE conference on computer vision and pattern recognition. (2016)
[6] Inoue, T. – Chaudhury, S. – De Magistris, G. – Dasgupta, S.. “Transfer Learning from Synthetic to Real Images Using Variational Autoencoders for Precise Position Detection.” 2018 25th IEEE International Conference on Image Processing (ICIP) (2018)
[7] Hinton, G. E. – Salakhutdinov, R. R.. “Reducing the dimensionality of data with neural networks.” Science, 313, 504-507 (2006)
[8] Kingma, D. P. – Welling, M.. “Auto-Encoding Variational Bayes” ArXiv abs/1312.6114 (2013)
[9] Goodfellow, I. J. – Pouget-Abadie, J. – Mirza, M. – Xu. B. – Warde-Farley, D. – Ozair, S. – Courville, A. – Bengio, Y.. “Generative adversarial nets.” In Proceedings of the 27th International Conference on Neural Information Processing Systems – Volume 2 (NIPS’14) (2014)
[10] Makhzani, A. – Shlens, J. – Jaitly, N – Goodfellow, I. – Frey, B.. “Adversarial Autoencoders.” ArXiv abs/1511.05644 (2015)
[11] Tremblay, J. – To., T – Birchfield, S.. “Falling Things: A Synthetic Dataset for 3D Object Detection and Pose Estimation.” 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) (2018)
[12] Kunfeng, W. – Yue, L. – Yutong, W. – Fei-Yue, W.. “Parallel imaging: A unified theoretical framework for image generation.” 2017 Chinese Automation Congress (CAC) (2017)
[13] Tsirikoglou, A. – Kronander, J. – Wrenninge, M. – Unger, J.. “Procedural Modeling and Physically Based Rendering for Synthetic Data Generation in Automotive Applications.” ArXiv abs/1710.06270 (2017)





