In un mercato internazionale sempre più basato sui dati, sulle informazioni digitali e sulle infrastrutture informatiche, uno degli obiettivi strategici ormai in cima all’agenda di ogni organizzazione è rappresentato dall’acquisizione di strumenti in grado di elaborare, aggregare, analizzare, studiare ed esaltare il proprio patrimonio informativo per generare servizi a valore aggiunto e incrementare le quote di mercato. Partendo da tali considerazioni, è possibile comprendere le ragioni che sottendono allo straordinario successo di “Hadoop as a service (HaaS)”, noto anche come Hadoop nel cloud, che rappresenta un framework di analisi dei big data che archivia e analizza le informazioni sulla grande nuvola digitale utilizzando le funzionalità di “Hadoop”, ossia di una piattaforma software open source ideata da Apache Software Foundation.
Lanciato nel 2006 nel solco tracciato dalla MapReduce di Google e dal Google File System, Hadoop si è immediatamente affermato come un punto di riferimento internazionale per la gestione delle sempre maggiori quantità di dati detenute dalle aziende di tutto il mondo.
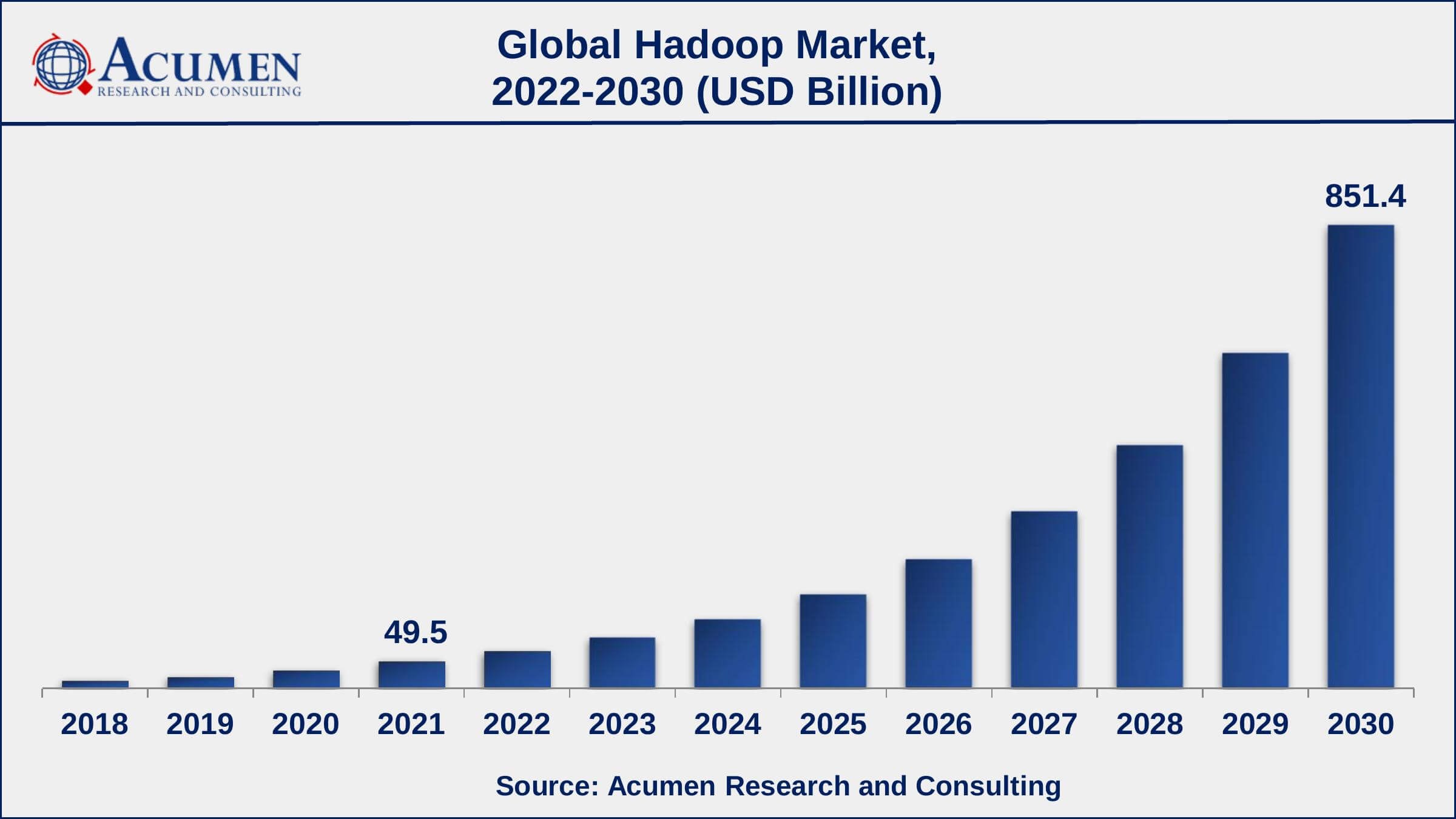
La diffusione di tale strumento è avanzata ad un ritmo così frenetico e repentino da aver ispirato anche numerosi studi economici come quello realizzato dalla Acumen Research and Consulting (ARC), secondo il quale Hadoop raggiungerà nel 2030 un valore di mercato di oltre 815 miliardi di dollari ed un tasso annuo di crescita composto (più comunemente noto come CAGR) del 37,3% dal 2022 al 2030, generando 181 zettabyte di dati entro il 2025.

Fonte: https://www.acumenresearchandconsulting.com/hadoop-market
Fonte: https://www.acumenresearchandconsulting.com/hadoop-market
Video

Indice degli argomenti
Cos’è Hadoop
Apache Hadoop, come anticipato, è un framework open source utilizzato per archiviare ed elaborare in modo efficiente set di dati di grandi dimensioni di dimensioni comprese tra gigabyte e petabyte di dati.
Hadoop, in estrema sintesi, consente di raggruppare più computer in cluster per analizzare più rapidamente enormi set di dati in parallelo.
Hadoop è costituito da quattro moduli principali:
- Hadoop Distributed File System (HDFS): un file system distribuito che funziona su hardware standard o di fascia bassa. HDFS offre un throughput dei dati migliore rispetto ai file system tradizionali, oltre a un’elevata tolleranza agli errori e al supporto nativo di set di dati di grandi dimensioni.
- Yet Another Resource Negotiator (YARN): gestisce e monitora i nodi del cluster e l’utilizzo delle risorse. Pianifica lavori e attività.
- MapReduce: un framework che aiuta i programmi a eseguire il calcolo parallelo sui dati. L’attività mappa prende i dati di input e li converte in un set di dati che può essere calcolato in coppie chiave-valore. L’output dell’attività della mappa viene consumato riducendo le attività per aggregare l’output e fornire il risultato desiderato.
- Hadoop Common: fornisce librerie Java comuni che possono essere utilizzate in tutti i moduli.
Hadoop semplifica l’utilizzo di tutta la capacità di archiviazione ed elaborazione nei server del cluster e l’esecuzione di processi distribuiti su ingenti quantità di dati oltre a fornire gli elementi costitutivi su cui è possibile costruire altri servizi e applicazioni.
Grazie a tali importanti caratteristiche, in qualche modo uniche nel panorama IT internazionale, l’ecosistema lanciato originariamente da Apache è cresciuto notevolmente nel corso degli anni, coinvolgendo sempre più aziende, attirando fornitori di servizi cloud intenzionati a veicolare le funzionalità di gestione dei dati ai propri clienti ed arrivando a includere numerose applicazioni finalizzate a raccogliere, archiviare, elaborare, analizzare e gestire i big data.
Alcune delle applicazioni più popolari sono:
 |  |  |
| Si tratta di un sistema di elaborazione distribuito open source comunemente utilizzato per i carichi di lavoro di Big Data, che utilizza il caching in memoria e l’esecuzione ottimizzata per prestazioni veloci e supporta l’elaborazione batch generale, l’analisi dei flussi, l’apprendimento automatico, i database a grafo e le query ad hoc. | È un motore di query SQL distribuito open source ottimizzato per l’analisi ad hoc dei dati a bassa latenza che supporta lo standard ANSI SQL, comprese query complesse, aggregazioni, join e funzioni di finestra. | Consente agli utenti di sfruttare Hadoop MapReduce utilizzando un’interfaccia SQL, abilitando l’analisi su vasta scala, oltre al data warehousing distribuito e tollerante ai guasti. |
 |  | |
| Rappresenta un database open source, non relazionale, che permette di creare un vero e proprio archivio di big data fortemente distribuito e scalabile, strettamente coerente e in tempo reale a tabelle con miliardi di righe e milioni di colonne. | Mette a disposizione degli utenti un “taccuino” interattivo che consente l’esplorazione dinamica dei dati. | |
Hadoop as a service (HaaS)
In linea con l’evoluzione delle tecnologie informatiche e soprattutto con la vera e propria trasformazione imposta dall’avvento del Cloud, negli ultimi anni sono sorte numerose proposte commerciali nelle quali Hadoop è offerto sotto forma di servizio ospitato sulla nuvola virtuale.
Grazie a Hadoop as a service (HaaS), invero, gli utenti non sono più chiamati a investire o installare un’infrastruttura presso data center di proprietà ma al contrario possono fruire delle funzionalità della piattaforma in maniera scalabile, flessibile e personalizzabile.
Video

Utilizzando la licenza open source con la quale è distribuito il framework originario, che naturalmente costituisce il cuore pulsante di ogni piattaforma HaaS, sono sorte nel corso del tempo numerose alternative basate sul cloud che offrono i servizi di Hadoop in maniera più o meno diversificata.
Tra i grandi vantaggi derivanti dalle versioni cloud è possibile menzionare:
- il supporto fornito per l’utilizzo del framework Hadoop nel contesto aziendale di riferimento.
- la gestione dei cluster Hadoop, finalizzata a distribuire i dati e i carichi di lavoro in CED geograficamente distanti tra loro, garantendo efficacia, efficienza ed economicità ma anche salvaguardando i dati rispetto ad eventi avversi di varia natura (blackout, terremoti, inondazioni, incendi, etc).
- la possibilità di utilizzare linguaggi di programmazione alternativi, con l’obiettivo di rendere quanto più semplice possibile l’interlocuzione digitale e l’integrazione dei dati aziendali con quelli custoditi ed elaborati su HaaS.
- la realizzazione di cruscotti direzionali personalizzabili e intuitivi, che consentono di ottenere dei veri e propri strumenti a supporto delle decisioni strategiche (conosciuti anche come DSS – Decision support system).
- il forte orientamento alla sicurezza che diviene parte integrante dell’intera infrastruttura ed è, a sua volta, rivenduta come un “servizio” all’utente finale.
I vantaggi di Haas per le aziende
L’esecuzione dei servizi HaaS permette, com’è naturale attendersi, di coniugare tutti i vantaggi connessi a due tecnologie “disruptive” quali il Cloud e i Big data, consentendo alle aziende di ottenere strumenti estremamente importanti per migliorare la propria produttività senza la necessità di dotarsi di una infrastruttura fisica aggiuntiva ma anche di personale in grado di gestire complessi sistemi informativi.
Attraverso l’analisi delle informazioni a vario titolo gestite nel corso dei propri processi aziendali è possibile non solo estrarre nuova conoscenza ma soprattutto intercettare i cosiddetti “segnali deboli”, orientando le scelte strategiche verso i nuovi orientamenti del mercato.
A titolo esemplificativo, è possibile:
- individuare tipologie di acquirenti accomunati da abitudini di acquisto e caratteristiche sociodemografiche quali, a titolo di esempio, l’età anagrafica, la provenienza, il titolo di studio;
- orientare le proprie decisioni strategiche sulla scorta di informazioni provenienti dai sistemi in uso presso l’azienda e, pertanto, direttamente connesse al proprio “Core Business”;
- valorizzare il patrimonio informativo aziendale che troppo spesso è sottovalutato ma, al contrario, può costituire un vero e proprio asset di fondamentale importanza per aumentare la competitività ed acquisire nuove quote di mercato.
- determinare, attraverso meccanismi di inferenza, analisi ed elaborazioni, i rapporti di causa-effetto intercorrenti tra variabili tra loro a vario titolo connesse. Ad esempio, assumendo che la quantità di capitale investita per pubblicizzare un prodotto determini l’importo delle sue vendite, è possibile utilizzare l’analisi di regressione per quantificare in termini numerici la relazione tra pubblicità e vendite.
- identificare i clienti maggiormente soggetti al rischio abbandono, in quanto, ad esempio, non perfettamente soddisfatti dei prodotti o dei servizi di assistenza e customer care, e adottare le conseguenti strategie per impedirlo, attraverso promozioni mirate, scontistiche particolari o anche modifiche alla produzione ed alla commercializzazione;
- studiare le abitudini di acquisto dei clienti nella vendita al dettaglio, trovando associazioni su diversi prodotti comprati, permettendo, in ultima battuta, l’adozione di strategie di marketing fortemente personalizzate;
- predire l’influenza dell’andamento generale dei mercati su determinate zone geografiche o anche su particolari tipologie di prodotti e servizi;
Come migliorare la competitività dell’azienda con Haas
Per comprendere al meglio le dimensioni raggiunte nel corso degli anni da HaaS, è sufficiente considerare che, allo stato attuale, Hadoop su Cloud sia utilizzato da aziende operanti praticamente in tutti i settori del commercio e dell’industria.
Nella tabella riportata di seguito sono riportati alcuni tra i principali casi di successo descritti sul sito di Aptude con l’obiettivo di dimostrare come l’utilizzo dei HaaS possa aiutare anche aziende leader del mercato ad apportare innovazioni in grado di migliorare ulteriormente la propria organizzazione.
 |  |  |
| Una delle sfide principali che Facebook ha affrontato sin dalla propria nascita è quella correlata allo sviluppo di una metodologia scalabile, flessibile ed efficiente finalizzata ad archiviare ed elaborare i dati generati dagli utenti della piattaforma. In tale contesto il colosso statunitense ha avviato una serie di progetti basati su Hadoop che hanno condotto all’implementazione di funzionalità quali “Facebook Lexicon” ma anche alla realizzazione di numerosi cluster Hadoop, che arrivano ad utilizzare oltre 2500 core di CPU e 1 PetaByte di spazio su disco. Facebook sta caricando ogni giorno oltre 250 gigabyte di dati compressi (oltre 2 terabyte non compressi) nel file system Hadoop e ha centinaia di lavori in esecuzione ogni giorno su questi set di dati. L’elenco dei progetti che utilizzano questa infrastruttura si è moltiplicato, da quelli che generano banali statistiche sull’utilizzo del sito, ad altri utilizzati per combattere lo spam e determinare la qualità delle applicazioni. Una parte incredibilmente ampia dei loro ingegneri ha svolto lavori Hadoop a un certo punto. La rapida adozione di Hadoop su Facebook è stata possibile grazie a due principali motivazioni:
| Ebay ha sviluppato una piattaforma, chiamata Kylin, basata su Hadoop, che permette di ottimizzare l’archiviazione delle informazioni sfruttando le tecnologie già utilizzate in ambito aziendale. I dati, in particolare, sono archiviati in Apache Hive, che svolge anche un ruolo di interfaccia tra gli sviluppatori e il framework Hadoop. Ebay ha sviluppato anche alcune interessanti funzionalità complementari come l’integrazione con strumenti di business intelligence come la famosa piattaforma “Tableau Inc.”, la compressione e il monitoraggio dello storage. Le versioni future di Kylin aggiungeranno anche un migliore supporto per ulteriori paradigmi di elaborazione, tra i quali OLAP. | Anche il colosso dei Dbms Oracle fa affidamento su Hadoop per gestire in maniera efficiente l’enorme mole di dati elaborata dai propri database. Nel gennaio 2012, in particolare, Oracle ha annunciato un accordo congiunto con Cloudera, un distributore di software e servizi basati su Hadoop,per fornire una distribuzione e strumenti Apache Hadoop per “Oracle Big Data Appliance”. Oracle Big Data Appliance, in particolare, rappresenta un sistema ingegnerizzato di hardware e software che incorpora la distribuzione di Cloudera, inclusi Apache Hadoop (CDH) e Cloudera Manager, nonché una distribuzione open source di Oracle NoSQL Database Community Edition, Oracle HotSpot Java Virtual Machine e Oracle Linux in esecuzione sui server Sun di Oracle. |
 |  | |
| Salesforce ha integrato Hadoop sia nelle proprie applicazioni interne, come quella che permette la gestione delle metriche di prodotto, sia nei prodotti forniti alla clientela, come, ad esempio, Chatter. Le metriche di prodotto, in particolare, sono importanti per i Product Manager, per comprendere l’utilizzo e l’adozione delle loro funzionalità, ma anche per il management che deve adottare decisioni di tipo strategico. Il team di lavoro di Salesforce ha anche scritto un programma Java personalizzato per generare automaticamente script in grado di utilizzare funzionalità predefinite di Hadoop. | Yahoo può essere considerato come il più grande contributore di Hadoop che, di fatto, è diventato parte integrante dell’architettura del famoso motore di ricerca. Yahoo gestisce i cluster Hadoop più grandi del mondo, collabora con istituzioni accademiche e altre grandi aziende nella ricerca avanzata sul cloud computing ei suoi ingegneri sono i principali partecipanti alla comunità Hadoop. | |
In quali ambiti aziendali si usa Haas
Come anticipato in precedenza i settori di applicazione del data mining sono innumerevoli e abbracciano praticamente tutte le sfere dell’attività umana spaziando dal marketing per arrivare all’economia, alla finanza ma anche alla scienza, alle tecnologie dell’informazione e della comunicazione, alle statistiche, all’industria e praticamente ad ogni altro ambito nel quale è necessario trattare, analizzare ed elaborare dati con l’obiettivo di ottenere nuova conoscenza.
Di seguito sono riportate alcune tra le applicazioni più diffuse ed importanti di Hadoop:
Analisi dei dati di clickstream
Hadoop può essere utilizzato per analizzare i dati di clickstream e classificare gli utenti esaminandone le preferenze. Si rivela quindi decisivo per le aziende di marketing che desiderano pubblicare inserzioni più efficaci grazie allo studio dei dati di clickstream e dei log delle impressioni.
Elaborazione di log
Il framework, invero, è ideale per elaborare i log generati da applicazioni Web e app mobili. Hadoop consente di trasformare petabyte di dati parzialmente strutturati o del tutto non strutturati in informazioni strategiche su applicazioni e utenti.
Analisi con capacità di più petabyte
Le applicazioni dell’ecosistema di Hadoop, ad esempio Hive, permettono agli utenti di sfruttare Hadoop MapReduce tramite interfaccia SQL, consentendo analisi su data warehouse distribuiti, di grandi dimensioni e con tolleranza agli errori. Usa Hadoop per memorizzare i dati e consentire agli utenti di inviare query su dati di qualsiasi dimensione.
Genomica
La mappatura di un genoma, con la sua enorme mole di dati, è un’applicazione che sfrutta particolarmente la rapidità e l’efficienza fornite da Hadoop. AWS ha reso pubblici i dati del progetto 1000 Genomes perché fossero disponibili gratuitamente alla comunità scientifica.
Estrazione, trasformazione e caricamento dei dati
Per la sua natura scalabile e i costi ridotti, Hadoop è un servizio ideale per i carichi di lavoro di estrazione, trasformazione e caricamento dei dati o ETL (extract transform load), ad esempio raccolta, ordinamento, unione e aggregazione di set di dati di grandi dimensioni per l’utilizzo con sistemi a valle.
I principali fornitori Hadoop as a service
La crescente popolarità di Hadoop ha indotto tutti i principali player mondiali a implementare servizi HaaS e a mettere a disposizione dei propri utenti funzionalità, architetture ed ecosistemi sempre più evoluti ed in grado di rispondere alle sempre più variegate e complesse esigenze delle aziende moderne.
Di seguito è riportata una rapida carrellata delle principali soluzioni disponibili oggi sul mercato.
Amazon EMR

Amazon EMR (precedentemente Amazon elastic MapReduce) è una piattaforma di cluster che semplifica l’esecuzione di framework di Big Data per elaborare e analizzare grandi quantità di informazioni.
Il framework, in particolare, consente inoltre di trasformare e spostare grandi quantità di dati all’interno e all’esterno di altri datastore e database AWS, come Amazon Simple Storage Service (Amazon S3) e Amazon DynamoDB.
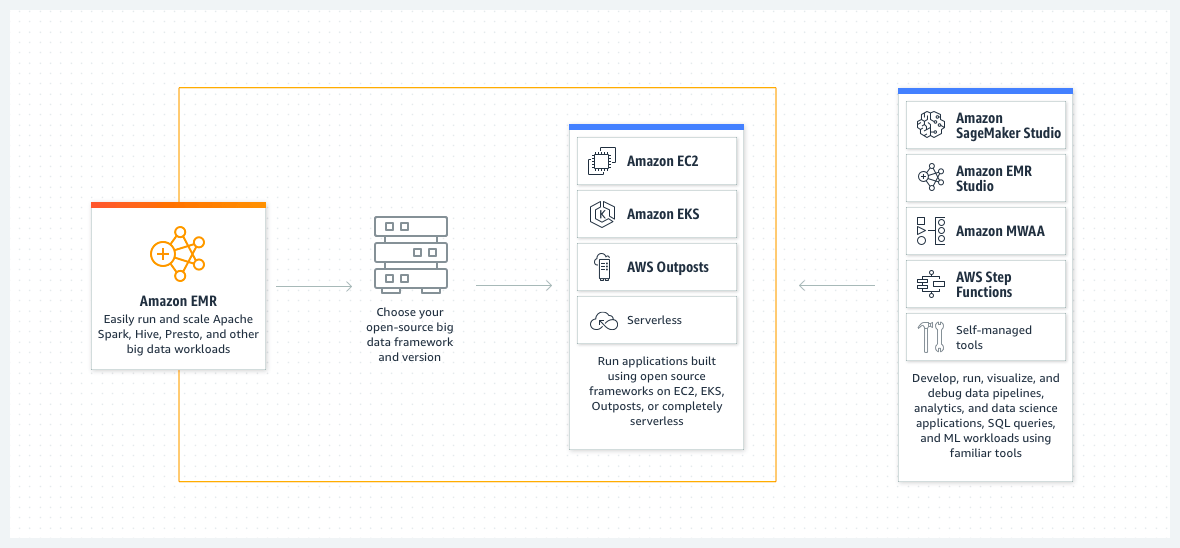
Con Amazon EMR è possibile creare e gestire cluster elastici completamente configurati di istanze che eseguono Hadoop e altre applicazioni del suo ecosistema.
È possibile, in particolare, avviare un nuovo cluster Hadoop in modo dinamico e con la massima semplicità, oppure aggiungere server a un cluster Amazon EMR esistente, riducendo in modo significativo il tempo necessario per rendere disponibili nuove risorse agli utenti e ai data scientist.
Hadoop sulla piattaforma AWS permette di migliorare l’agilità riducendo i costi e il tempo necessari per allocare risorse per esigenze di sperimentazione e sviluppo.
Apache Hadoop
Apache Hadoop può essere considerato come il capostipite di tutti i progetti basati su Hadoop: si tratta del primo framework della famiglia che è stato sotto una licenza libera che supporta applicazioni distribuite con elevato accesso ai dati, permettendo alle applicazioni di lavorare con migliaia di nodi e petabyte di dati.

Il nome del progetto è stato scelto dal suo creatore Doug Cutting, che si è ispirato all’elefante di pezza di suo figlio. In origine fu sviluppato per supportare la distribuzione per il progetto del motore di ricerca “Nutch”.
Cloudera Enterprise

La distribuzione Hadoop più popolare al mondo è molto probabilmente la piattaforma CDH di Cloudera.
Rilasciata con licenza open source al 100%, CDH comprende tutti i principali componenti dell’ecosistema Hadoop per archiviare, elaborare, scoprire, modellare e fornire dati illimitati ed pensato per soddisfare i più elevati standard aziendali in termini di stabilità e affidabilità.
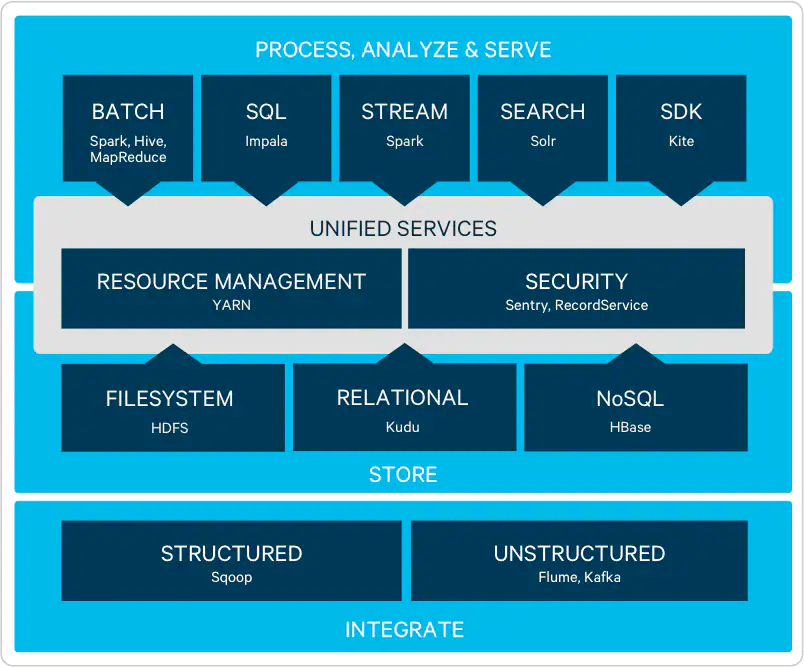
Cloudera punta, in particolare, a garantire una transizione quanto più possibile fluida e snella dei dati dalle applicazioni utilizzate dalle imprese verso l’ecosistema Hadoop.
Azure HDInsight
Azure HDInsight è una piattaforma finalizzata a semplificare la gestione di grandi moli da dati attraverso l’utilizzo e l’integrazione di framework quali Apache Spark, Apache Hive, LLAP, Apache Kafka e Apache Hadoop.

HDInsight consente di aumentare o ridurre in maniera estremamente flessibile i carichi di lavoro, di proteggere i dati aziendali usando la Rete virtuale di Azure, la crittografia e l’integrazione con Azure Active Directory.
Azure HDInsight si integra con i log di Monitoraggio di Azure per fornire una singola interfaccia che consente di monitorare tutti i cluster.
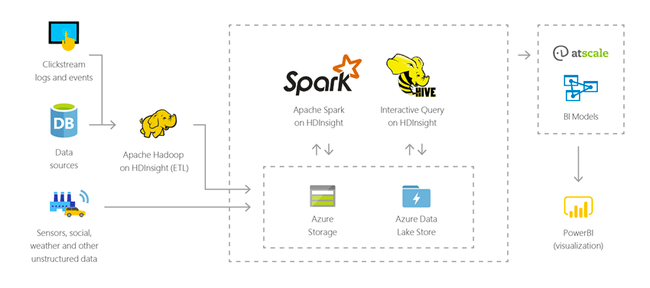
Azure HDInsight consente di usare strumenti di produttività avanzati per Hadoop e Spark con gli ambienti di sviluppo più diffusi. Questi ambienti di sviluppo includono il supporto di Visual Studio, VSCode, Eclipse e IntelliJ per Scala, Python, Java e .NET.
È possibile estendere i cluster HDInsight con componenti installati (Hue, Presto e così via) usando azioni di script, aggiungendo nodi perimetrali o integrando con altre applicazioni certificate big data. HDInsight consente un’integrazione semplice con le soluzioni big data più popolari con una distribuzione con un clic.
Google Cloud Dataflow

Dataflow è un servizio di Google cloud di tipo serverless (ossia completamente dal fornitore che alloca dinamica, in base alle esigenze del cliente, le risorse sulla propria infrastruttura server), che permette la gestione di flussi dati comprimendo al minimo la latenza ed i tempi di elaborazione, implementando scalabilità automatica e ottimizzazione dei costi.
Secondo le intenzioni del colosso statunitense il prodotto è pensato per permettere agli utenti di concentrarsi sulla programmazione e sulla logica di elaborazione dei dati anziché sulla gestione dei cluster di server.
Dataflow, invero, può essere integrato con Stackdriver, che consente di monitorare e risolvere gli problemi delle pipeline mentre sono in esecuzione e si presenta come un un punto di integrazione centralizzato in cui è possibile aggiungere, tra l’altro, modelli di machine learning Tensorflow per elaborare pipeline di dati.
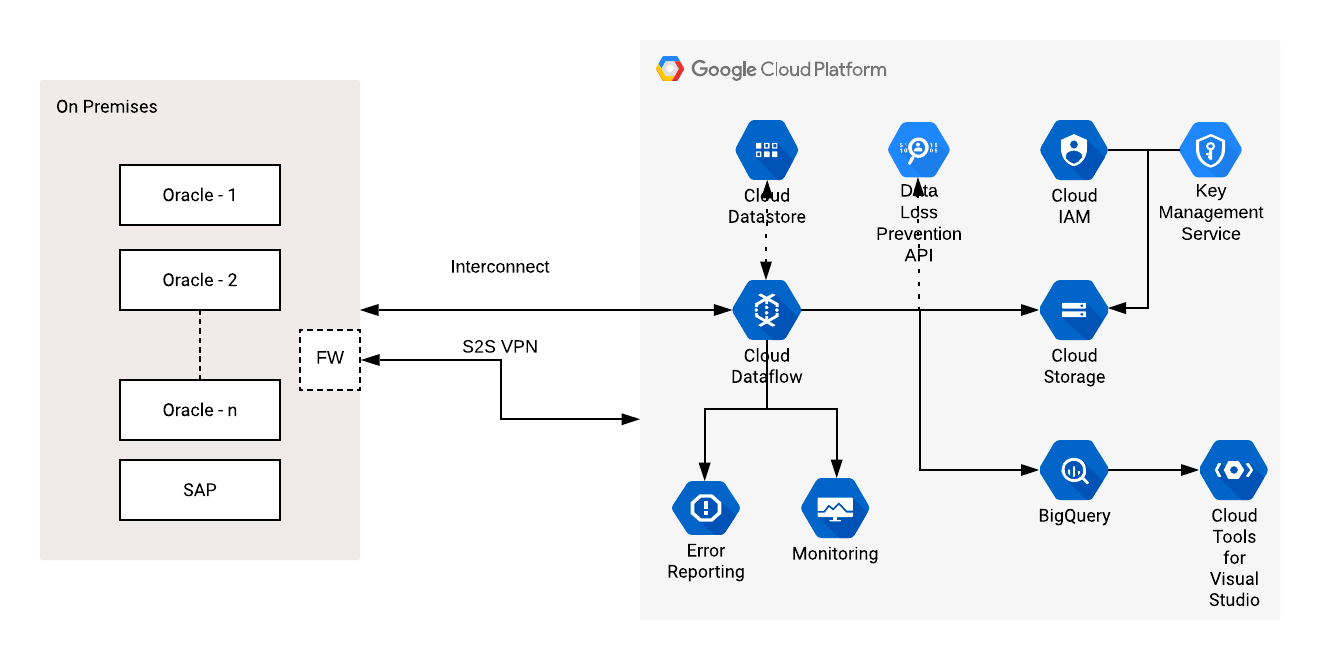
Tra le caratteristiche principali, degne di nota sono le seguenti:
- È un framework estremamente versatile e “multifunzionale”, in quanto, tra le altre cose, aggrega al proprio interno funzionalità quali ETL, elaborazione in batch e lo streaming di analisi in tempo reale.
- È stato sviluppato per superare i noti problemi di prestazioni di MapReduce che, se da un lato costituisce uno dei pilastri sui quali è stato costruito l’intero framework, dall’altro ha rivelato nel corso del tempo talune problematiche connesse soprattutto alla velocità di elaborazione di ingenti quantità di dati.
- Il modello di codifica proposto è abbastanza intuitivo e permette di utilizzare i linguaggi di programmazione ad oggetti (il primo SDK distribuito è per Java ma ne sono annunciati altri) oltre all’ormai storico SQL.
Video