
Hive Apache è un sistema di data warehouse progettato per Apache Hadoop, per svolgere attività di aggregazione, interrogazione e analisi dei dati e in particolare Big Data analytics.
I data engineer, che aiutano a raccogliere, organizzare e riordinare i dati che il data scientist usa per costruire le analisi, hanno familiarità con le tecnologie di base di Hadoop. Proprio a partire da MapReduce, Apache Hive e Apache Pig. Ecco cos’è Hive e quali benefici offre alle aziende.

Introduzione a Hive Apache
Hive Apache è un framework di data warehousing open-source che fornisce un’interfaccia SQL-like per interrogare i dati memorizzati in Hadoop. Consente agli utenti di eseguire query ad hoc, analisi dei dati e processa grandi volumi di dati strutturati (o semi-strutturati).
Inoltre utilizza il linguaggio HiveQL, simile al linguaggio SQL tradizionale, per definire le query e le operazioni sui dati. Hive converte le query HiveQL in una serie di job MapReduce (costituito da 4 componenti), che vengono eseguiti su un cluster di computer Hadoop per elaborare i dati. Ciò rende Hive particolarmente versatile per elaborare grandi dataset distribuiti.
Hive è ampiamente utilizzato nell’ambito del data warehousing e dell’analisi dei dati, in particolare quando si lavora con grandi quantità di dati strutturati o semi-strutturati.

Come funziona Hive Apache: panoramica dettagliata
Per funzionare, le query in Hive utilizzano HiveQL, il linguaggio di definizione delle tabelle di Hive. Hive permette di strutturare i dati principalmente non strutturati. Per esempio, file di testo con i campi delimitati da caratteri specifici, l’istruzione HiveQL realizza una tabella di dati dove a delimitare sono gli spazi. Una volta definita la struttura, è possibile utilizzare HiveQL per interrogare i dati senza necessità di conoscere Java o MapReduce.
HDInsight offre diversi tipologie di cluster ottimizzati per specifici carichi di lavoro. I tipi di cluster più comunemente utilizzati per le query Hive sono: Interactive Query; Hadoop; Spark; Hbase.
Inoltre è possibile usare Hive con HDInsight con tool di HDInsight per Visual Studio Code su multipiattaforma (o per Visual Studio su Windows), Vista di Hive su browser, Client Beeline, Rest API o Windows PowerShell.
Hive fornisce inoltre il Hive supporto a serializzatori/ deserializzatori personalizzati (come JSON) per dati complessi o strutturati in modo irregolare.
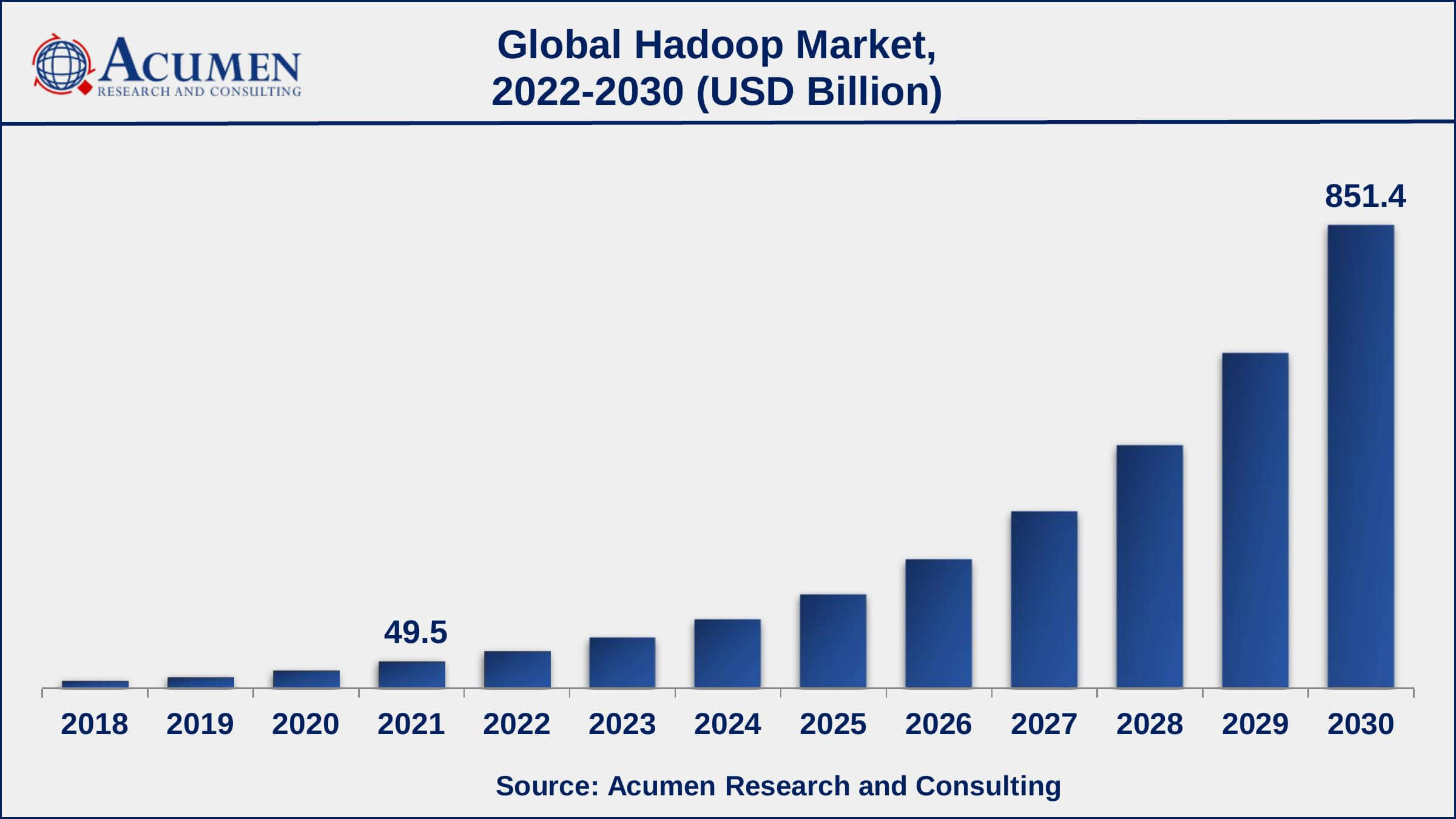
Perché Hive Apache è utile per le aziende: vantaggi e casi d’uso
Il framework di data warehouse open source per l’elaborazione e l’analisi di grandi quantità di dati strutturati, offre numerosi vantaggi alle aziende: la scalabilità, la semplicità d’uso, l’integrazione con l’ecosistema Hadoop, il supporto per dati strutturati e semi-strutturati, l’ecosistema di tool e plug-in.
Hive può infatti gestire grandi quantità di dati distribuiti su cluster di server, consentendo alle aziende la scalabilità, dunque l’opportunità di elaborare e analizzare dati di grandi dimensioni in modo efficiente.
Il linguaggio di query HiveQL semplifica inoltre agli utenti finali, che conoscono SQL, la scrittura di query e la possibilità di interrogare i dati senza dover imparare nuove competenze o linguaggi di programmazione complessi.
Hive è progettato per funzionare su Apache Hadoop, che è un framework di elaborazione distribuita per il processing di grandi quantità di dati. L’integrazione con l’ecosistema Hadoop consente alle aziende di sfruttare i vantaggi di Hadoop, come l’archiviazione distribuita e l’elaborazione parallela.
Hive Apache può gestire sia dati strutturati che semi-strutturati, permettendo alle imprese di analizzare una vasta gamma di tipi di dati, tra cui file di log, dati di social media, dati di clickstream e altro ancora, offrendo dunque un supporto per dati strutturati e semi-strutturati.
Infine supporta un ampio ecosistema di strumenti e plug-in che consentono alle aziende di integrare Hive con altre tecnologie e strumenti di analisi dati, come Apache Spark, Apache Pig e Apache HBase.

Come integrare Hive Apache nel workflow dei dati aziendali
Per integrare Hive Apache nel workflow dei dati aziendali, è possibile seguire alcuni passaggi, sfruttando le potenti funzionalità per l’elaborazione e l’analisi dei dati.
Bisogna installare e configurare Hive, installando Hive nel proprio ambiente di dati e seguendo la documentazione ufficiale di Apache Hive per l’installazione e la configurazione dettagliate.
Occorre poi creare tabelle Hive, grazie a HiveQL per generare le tabelle Hive che rappresenteranno i dati aziendali. Puoi definire lo schema, i tipi di dati e le relazioni tra le tabelle.
In seguito si importano i dati aziendali nelle tabelle Hive, tramite il comando LOAD. Si caricano i dati da file locali, file Hadoop Distributed File System (HDFS) o da altre origini di dati supportate.
I passaggi
La query dei dati sfrutta HiveQL per eseguire query sui dati aziendali. Permette di utilizzare le funzioni HiveQL per filtrare, aggregare e trasformare i dati secondo le proprie esigenze. Le query vengono eseguite su Hadoop MapReduce o su altri framework di esecuzione supportati da Hive.
Hive può essere integrato con altri strumenti e tecnologie per migliorare il tuo workflow dei dati aziendali. Per esempio, è possibile utilizzare Apache Spark per eseguire analisi in-memory sui dati Hive o utilizzare Apache Kafka per l’elaborazione dei dati in tempo reale.
Offre diverse opzioni di ottimizzazione per migliorare le prestazioni delle query. Consente di utilizzare tecniche come la partizionamento dei dati, l’indicizzazione o la progettazione di tabelle ottimizzate per migliorare le prestazioni delle query su grandi volumi di dati.
Bisogna garantirsi di monitorare le prestazioni delle query Hive e di gestire le risorse in modo efficiente. Permette di utilizzare strumenti di monitoraggio come Apache Ambari o Cloudera Manager per tenere traccia delle metriche di performance e gestire le risorse di cluster.
La cyber security
La sicurezza dei dati è garantita implementando misure di sicurezza per proteggere i dati aziendali sensibili. Permette di utilizzare Hive per abilitare l’autenticazione degli utenti, l’autorizzazione basata sui ruoli e la crittografia dei dati.

Hive Apache vs. altri sistemi di archiviazione dati: quale scegliere
La scelta del sistema di archiviazione dati dipende dalle specifiche esigenze e requisiti del tuo caso d’uso. Ecco una panoramica di Hive Apache rispetto ad altri sistemi di archiviazione dati comuni.
In generale, Hive Apache è una scelta popolare per l’elaborazione dati su larga scala, soprattutto quando si lavora con grandi volumi di dati strutturati. Tuttavia, prima di prendere una decisione definitiva sul sistema di archiviazione dati da impiegare, è importante valutare attentamente le proprie esigenze specifiche: prestazioni richieste, scalabilità, complessità delle query e integrazione con altri strumenti.

Hive Apache vs. Apache HBase
Hive Apache e HBase sono entrambi progetti di Apache, ma si differenziano per le loro caratteristiche principali. Hive è un framework per l’elaborazione dei dati basato su Hadoop, che consente di eseguire query strutturate su grandi quantità di dati archiviati in formato tabellare. HBase, invece, è un database NoSQL distribuito che offre accesso ad alta velocità ai dati tramite chiave primaria. Se l’impresa ha bisogno di eseguire analisi ad-hoc su grandi quantità di dati strutturati, Hive Apache potrebbe essere la scelta migliore. Se invece hai bisogno di un accesso rapido e scalabile ai dati basato su chiave primaria, potresti considerare HBase.
Hive Apache vs. Apache Cassandra
Hive Apache e Cassandra sono entrambi sistemi di archiviazione distribuiti, ma si differenziano per le loro caratteristiche principali. Hive è ottimizzato per l’elaborazione di query ad-hoc su grandi quantità di dati, mentre Cassandra è un database NoSQL distribuito che si concentra sulla scalabilità orizzontale e la disponibilità dei dati. Se un’azienda necessita di eseguire analisi ad-hoc su grandi volumi di dati, Hive Apache potrebbe essere la scelta migliore. Se invece ha necessità di un sistema altamente scalabile e ad alta disponibilità per l’archiviazione e il recupero dei dati, potrebbe prfendere in considerazione Cassandra.
Hive Apache vs. Apache Spark
Hive Apache e Spark sono entrambi progetti di Apache, ma si differenziano per il modo in cui elaborano i dati. Hive utilizza il linguaggio di interrogazione HiveQL per eseguire query su dati strutturati, mentre Spark offre un’ampia gamma di funzionalità di elaborazione dati, tra cui l’elaborazione in-memory, l’elaborazione streaming e l’apprendimento automatico. Se l’impresa vuole eseguire query strutturate su grandi quantità di dati, Hive Apache potrebbe essere la scelta ideale. Se invece ha esigenza di un framework di elaborazione dati più flessibile e potente, potrebbe prendere in esame Spark.
Come usare Hive Apache per l’analisi dei Big Data: esempi pratici
Casi d’uso comuni per Hive Apache includono l’analisi dei dati di business, l’elaborazione dei dati di log, l’analisi dei Big Data di social media. Ma anche l’elaborazione dei dati di clickstream, l’analisi dei Big Data di marketing e molto altro ancora.
Hive Apache è utile per le aziende che devono elaborare grandi moli di dati strutturati e semi-strutturati in modo efficiente e scalabile.
Le migliori pratiche per il tuning delle prestazioni in Hive Apache
Le migliori pratiche per il tuning delle performance in Hive Apache permettono di ottimizzare l’esecuzione delle query, migliorando le prestazioni complessive. Ecco alcune delle migliori pratiche da seguire per il tuning delle prestazioni in Hive Apache: Partizionamento dei dati, indicizzazione, ottimizzazione delle query, configurazione delle risorse, compressione dei dati, gestione della cache, aggiornamento di Hive, monitoraggio delle prestazioni, utilizzo di strumenti esterni
Il tuning delle prestazioni in Hive Apache è un processo iterativo che richiede monitoraggio costantemente delle prestazioni. Bisogna testare diverse configurazioni e strategie di ottimizzazione, utilizzando i dati di monitoraggio per migliorare continuamente le prestazioni delle tue query.

Sicurezza e conformità nell’utilizzo di Hive Apache
La sicurezza e la conformità sono aspetti critici quando si utilizza Hive Apache o un altro sistema di archiviazione dati.
Come fare
La sicurezza e la conformità sono processi continui e richiedono un monitoraggio costante e l’implementazione di best practice di sicurezza. Bisogna coinvolgere esperti di sicurezza per garantire la conformità a policy e requisiti di sicurezza interni ed esterni.
Per garantire la sicurezza e la conformità nell’utilizzo di Hive Apache:
- Autenticazione degli utenti: L’accesso a Hive deve limitarsi solo agli utenti autorizzati. Puoi utilizzare meccanismi di autenticazione come Kerberos o LDAP per autenticare gli utenti prima di consentire loro l’accesso a Hive;
- Autorizzazione basata sui ruoli: per mette di controllare l’accesso agli oggetti Hive, come tabelle o database, definendo ruoli con privilegi specifici e assegnandolo agli utenti in base alle loro responsabilità;
- Crittografia dei dati: sfrutta la crittografia per proteggere i dati sensibili archiviati in Hive, crittografando i dati in transito grazie a SSL/TLS e quelli a riposo con strumenti come Hadoop Transparent Data Encryption (TDE) o HDFS encryption;
- Monitoraggio degli accessi: traccia gli accessi e le attività degli utenti in Hive, utilizzando strumenti di monitoraggio come Apache Ranger o Apache Sentry per registrare gli accessi e generare registri di audi;
- Gestione delle autorizzazioni: mantiene un controllo rigoroso sulle autorizzazioni degli utenti e delle ruoli in Hive. Assicurati che solo gli utenti autorizzati abbiano accesso alle operazioni di creazione, lettura, aggiornamento e cancellazione (CRUD) sui dati;
- Conformità normativa: Se la propria organizzazione è soggetta a normative specifiche, bisogna assicurarsi che l’utilizzo di Hive sia conforme ad esse. Per esempio, è necessario rispettare regolamenti come il GDPR o il PCI DSS ((Payment Card Industry Data Security Standard);
- Backup e ripristino, pianificando e adottando una strategia di backup e ripristino dei dati Hive per garantire la disponibilità e l’integrità dei dati in caso di incidenti o guasti.;
- aggiornamenti e patch: Hive e i componenti correlati devo essere sempre aggiornati con le ultime patch di sicurezza per proteggersi da vulnerabilità note.

Gestione e amministrazione di Hive Apache
Richiedono l’implementazione di diverse attività per garantire un corretto funzionamento del sistema.
La gestione e l’amministrazione di Hive Apache richiedono una conoscenza approfondita dei concetti di base di Hive, oltre a competenze di amministrazione di sistema e conoscenza delle best practice di gestione dei dati. Gli esperti di Hive e Hadoop garantiscono una corretta amministrazione del sistema.
Le principali attività di gestione e amministrazione di Hive Apache
Le attività per gestire amministrare Hive Apache sono:
- installazione e configurazione (come le connessioni ai servizi di archiviazione dei metadati come Apache Derby o MySQ)
- la gestione dei metadati; il monitoraggio delle query (dall’interfaccia utente di Hive, Apache Ambari o Cloudera Manager);
- la pianificazione delle risorse (con strumenti di gestione delle risorse come Apache YARN per allocare e monitorare le risorse di esecuzione);
- la gestione degli utenti e delle autorizzazioni (con meccanismi di autenticazione come Kerberos o LDAP e con un sistema di autorizzazione basato sui ruoli per controllare l’accesso agli oggetti Hive);
- backup e ripristino (strumenti di backup come Apache Hadoop Distributed File System, HDFS o strumenti di replica dei dati come Apache Falcon);
- aggiornamenti e patch;
- monitoraggio delle prestazioni;
- scalabilità e ridondanza (con l’utilizzo di cluster Hadoop distribuiti o soluzioni di alto livello come Apache Spark per migliorare la scalabilità e la ridondanza);
- sicurezza dei dati.

Hive Apache nel mondo aziendale: cosa aspettarsi
Apache Hive effettua l’analisi del data warehouse utilizzando un approccio basato su query. I dati vengono memorizzati in un ambiente distribuito, come Hadoop, e Hive fornisce un’interfaccia SQL-like chiamata HiveQL per interrogare e analizzare i dati.
Quando si esegue una query HiveQL, Hive converte la query in una serie di job MapReduce che vengono eseguiti su un cluster di computer Hadoop. Questi job vengono distribuiti e paralleli, consentendo di elaborare grandi quantità di dati in modo efficiente.
Hive supporta anche l’ottimizzazione delle query, che cerca di migliorare le prestazioni delle query riducendo il tempo di elaborazione. L’ottimizzazione delle query può includere la riduzione del numero di job MapReduce, l’utilizzo di join efficienti o l’utilizzo di tecniche di partizionamento e bucketing per migliorare l’accesso ai dati.
Inoltre, Hive supporta la creazione di tabelle esterne e la possibilità di definire schemi e metadati per i dati. Ciò consente di strutturare i dati in modo più organizzato e di applicare regole di business specifiche durante l’analisi.
In sintesi, Hive utilizza un approccio basato su query e sfrutta la potenza di Hadoop per analizzare grandi quantità di dati in modo distribuito e scalabile.















