Per quanto sia stata definita la professione più sexy degli ultimi anni, alla fine le domande restano sempre le stesse: chi è davvero il Data Scientist? Come opera? Quali strumenti usa? Quali competenze deve avere? Per Daniele Pietropaoli, Technical Sales and Solution Predictive Analytics in IBM Italia, «il Data scientist è quella figura che attraverso metodologie statistiche analizza i dati che l’azienda mette a sua disposizione per trovare le correlazioni su obiettivi specifici».
Un esempio concreto? «In ambito Telco – spiega Pietropaoli – è importante non solo conoscere il churn rate, ma soprattutto comprendere i motivi dell’abbandono. Per questo motivo, il Data Scientist correla le informazioni che l’azienda ha su ciascun cliente, storici, anagrafici, comportamentali, con altri dati esterni, di tipo economico o territoriale. Tutte queste informazioni insieme vengono portate nei motori analitici per comprendere quale è la variabile che porta all’abbandono».
Per maggiori approfondimenti su Big Data, Data Science e sul lavoro dei Data Scientist scarica il white paper
Al lavoro con i data scientist: una guida per cogliere le opportunità dei big data

Basta questa premessa per comprendere un primo punto chiave: per il Data scientist le competenze e il know how IT non sono sufficienti.
Servono conoscenze di business e serve, soprattutto, un metodo.
«Il Data scientist deve avere il know how tecnico che gli consente di muoversi attraverso le diverse tecnologie in tempi rapidi, ma gli servono anche le competenze di business, che lo aiutano a comprendere quali sono le variabili più importanti, gli hot layer, da prendere in considerazione. Deve saper scegliere le tecnologie più adeguate, identificando il metodo più corretto sulla base degli obiettivi da raggiungere».
Indice degli argomenti
Quali differenze tra Data scientist e Data analyst?
Sebbene ci siano molte aree di grigio, nelle quali sembra che Data Analyst e Data Scientist in fondo siano figure sovrapponibili, la differenza tra i due ruoli è in realtà netta.
«Il Data Analyst analizza i dati con skill metodologici di business intelligence. Questo significa che il lavoro di analisi si svolge su aree che già si sanno essere correlate, cosa che permette di escludere la casualità. Il Data Scientist, invece, prende in esame tutti i dati cercando le correlazioni senza conoscerne l’esistenza».
È un approccio agnostico, privo di preconcetti, quello del Data scientist, il quale ha una visione più ampia: ha un obiettivo di riferimento ma lavora con più strumenti su tutte le informazioni disponibili per scoprire quelle correlate tra loro.
IBM accompagna questi “esploratori” del ventunesimo secolo con una serie di strumenti in grado di supportarli in tutte le fasi della loro attività e, ancor di più, in grado di portarli ad acquisire quelle competenze necessarie per raggiungere gli obiettivi richiesti.
Da IBM una piattaforma per fare community
«Le nostre soluzioni accompagnano i Data Scientist lungo tutto il loro viaggio attraverso i dati. Per questo partiamo con una piattaforma di discovery di tipo analitico, pensata per il business».
Il riferimento è a Watson Analytics, che, spiega Pietropaoli, supporta i Data Scientist che vogliono fare discovery sui dati senza preconcetti: «Watson Analytics vede i dati e cerca tutte le correlazioni, gli andamenti, le variabili. Per questo siamo convinti che sia un aiuto importante anche per chi non conosce a fondo le tecnologie e ha dunque bisogno di uno strumento con degli importanti automatismi a supporto».
Ma la Data Discovery è solo il primo passo.
Servono poi piattaforme metodologiche, con funzionalità di Data Mining, che aiutino a identificare i modelli comportamentali.
«La nostra piattaforma comprende dei wizard che di fatto rendono disponibili maschere utilizzabili senza conoscere specifici linguaggi di programmazione. È una differenza davvero sostanziale rispetto al passato: laddove in precedenza ciascuno programmava per conto proprio, trattenendo per sé il risultato del proprio lavoro, oggi ci si muove sempre di più in una logica di condivisione e di apertura, una logica nella quale si mettono a fattor comune metodi e strumenti, nella quale si lavora su ambienti comuni».
Per IBM, dunque, la strada è quella di creare una community intorno alla propria piattaforma e questa community ha un nome e un indirizzo precisi: Data Science Experience (DSX). È uno strumento che aiuta i Data Scientist a comprendere come si muovono i dati, dove si lavora sulla metodologia per comprendere come far partire i processi.
«Di fatto con la nostra piattaforma noi siamo in grado di aiutare i Data Analyst che vogliono fare analisi di alto livello e hanno bisogno di capire come si muovono i dati, i Data Scientist che conoscono la metodologia ma preferiscono utilizzare schemi predefiniti invece che scrivere codice ex novo, e ancora le community open».
Open è meglio
Il tema della openness è caro a IBM che insiste sull’importanza della replicabilità e della riusabilità dei codici e dei modelli.
«C’è una forte volontà a non tenere per sé i risultati ma a condividerli, così come si condividono le analisi e le informazioni. È importante sapere di poter contare su una community per farlo».
In tutto questo, IBM mantiene anche alta l’attenzione sugli aspetti formativi nei confronti sia delle aziende sue clienti, sia dei Data Scientist: «Quando incontriamo clienti che conoscono la materia, il nostro compito è formarli sulle nuove piattaforme, anche condividendo analisi effettuate sui loro contesti specifici e lavorando spalla a spalla con loro. Poi, però, ci sono i clienti che hanno una conoscenza un po’ più limitata sulla Data Science e con loro il lavoro è quasi di evangelizzazione: li traghettiamo verso la Data Science, spiegando cosa la tecnologia può fare per loro e come la metodologia può supportarne il percorso».
Formazione, però, è anche nei confronti delle generazioni più giovani.
Per questo IBM ha attivato progetti in molte università, dalla Sapienza alla Normale alla Cattolica, dedicando giornate alla formazione sia tecnologica, sia metodologica.
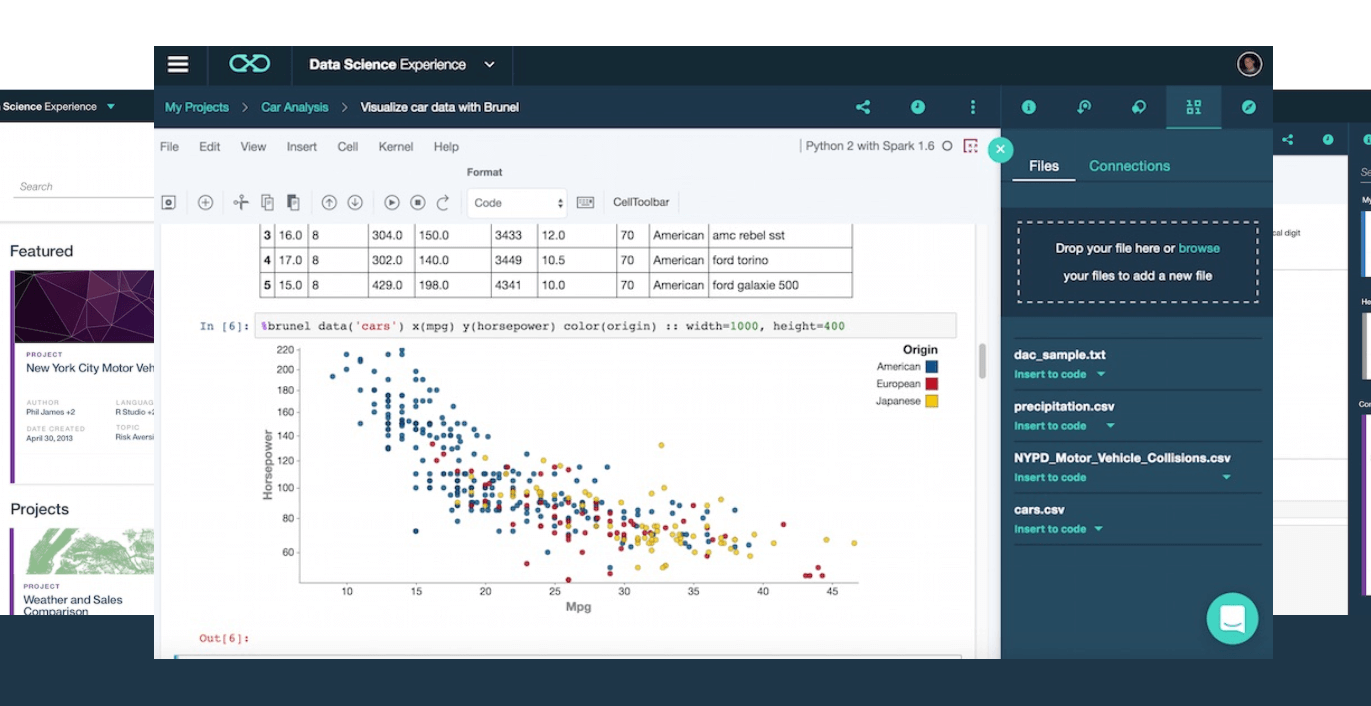
IBM DSX, la palestra dei Data scientist

Può essere davvero definita la palestra dei Data scientist: Data Science Experience è la porta di accesso a una serie di strumenti e servizi indirizzati sia a chi con la Data science ha già avuto a che fare, sia a chi si trova alle prime armi.
Tre gli obiettivi dichiarati:
- apprendere, con strumenti di apprendimento per neofiti, sia per chi vuole approfondire le proprie conoscenze
- creare, utilizzando gli strumenti open source messi a disposizione dalla stessa IBM
- collaborare, sia all’interno della community, sia all’interno del proprio team di lavoro.
Una la logica di utilizzo: Use what you know, learn what you don’t, usa ciò che sai, impara quello che non conosci.
DSX offre, nella definizione della stessa IBM, l’ambiente e gli strumenti che consentono di risolvere i loro problemi di business attraverso un’analisi collaborativa dei dati.
È una piattaforma tutta giocata intorno ai progetti, ciascuno associato a un motore di compute e allo storage. Il progetto prevede la possibilità di aggiungere collaboratori, dati, strumenti di analisi, consente di associare altri servizi funzionali al suo svolgimento.
Ma DSX è anche una community, nella quale sono disponibili risorse, come articoli, tutorial, esempi utili per imparare nuove tecniche, template, strumenti di analisi.
I dati possono essere caricati direttamente dal pc dell’utente oppure possono essere create connessioni a servizi cloud come Db2 Datawarehouse on Cloud, Amazon S3, Cloudant, PostgreSQL, database on premise, da Db2 a Netezza, da Oracle a SQLServer, o ancora possono essere utilizzati servizi di streaming dati.
Quanto all’analisi dei dati, tramite DSX è possibile scrivere Jupyter notebook in Python, Scala o R, usare il Flow Editor per creare modelli che utilizzano il Machine Learning per le analisi predittive, usare Rstudio direttamente all’interno di DSX, usare Stream Designer per raccogliere e analizzare gli stream di dati.
DSX, che consente un trial gratuito di 30 giorni, rende disponibili library open source come Brunel, PixieDust o SPSS Model e API per l’analisi dei dati e la visualizzazione dei dati, algoritmi di Machine Learning, tutti completi con metodi di calcolo, analisi e visualizzazione.
Soprattutto fornisce una porta di accesso diretto all’IBM Data Catalog e a molteplici risorse rese disponibili dalla società.















