
Tra le leggi non scritte dell’It ce n’è una, fondamentale e sempre valida, che dice “trash in, trash out”. Una regola che è diventata, se possibile, ancora più importante in seguito alla diffusione delle tecnologie relative ai ‘big data’, con i quali anche il dato-spazzatura ha assunto nuove dimensioni in quantità e qualità.

Che il tasso di adozione dei progetti big data sia oggi in rapida scesa è un dato di fatto: da un’indagine di Forrester Resarch aggiornata all’aprile 2015, risulta che oltre il 30% dei data manager è impegnato in questi mesi nell’implementare un sistema big data. Entro la fine dell’anno si prevede quindi che Hadoop, Cassandra, NoSQL e altre simili tecnologie saranno presenti nel 60% delle organizzazioni It. Non solo: se si guarda ai progetti che, secondo la stessa indagine, precedono quelli big data nell’agenda dei responsabili dati, ossia, nell’ordine, BI/Analytics, Enterprise DW e Customer DW (vedi figura 1), si vede subito che si tratta di cose che con i big data hanno un rapporto complementare, avendo come fine ultimo quello d’incrementare la base di sapere sulla quale costruire e condurre il business dell’impresa.
Ma, come abbiamo anticipato, l’impatto dei big data sui sistemi informativi aziendali ha un effetto negativo: quello di evidenziare ed accentuare i limiti e le falle delle piattaforme e dei sistemi di controllo della qualità dei dati. Lavorare coi big data significa dover trattare dati di tipo nuovo acquisiti da fonti inedite ed eterogenee; dover impostare politiche di governo diverse a seconda degli scenari d’uso (finanziari, marketing, sviluppo prodotti…); dover affrontare, con l’esplosione della data delivery, la crescita dei rischi legali, normativi e d’immagine; dover infine gestire le ormai inevitabili soluzioni BI self-service, che se da un lato abbattono le barriere tra i silos dati dipartimentali dall’altro tendono a creare una quantità di data-set più o meno elaborati (‘silos analitici’, li chiama Forrester) a livello individuale. Una vera sfida per chi deve garantire la data-quality necessaria perché un progetto big data dia i risultati attesi.
Indice degli argomenti
Un’offerta che si va sviluppando

Le difficoltà relative alla qualità e al governo dei big data non sono ignorate dai fornitori di tecnologia. Che, anzi, tendono a sottolineare le capacità di gestione e controllo delle loro soluzioni. Secondo Forrester, che ha analizzato il problema nello studio già citato, queste capacità, per quanto a volte efficaci, trovano un limite di fondo nell’essere autoreferenziali, nel non considerare cioè le necessità di governo imposte dalle politiche e dalle finalità del business, che sono quelle da cui deriva il valore aggiunto per utenti e decisori. Per questo Forrester ha voluto proporre uno schema per la big data governance che ne considera i cinque punti principali, e cioè: sicurezza, qualità, life-cycle management, master data management e metadata management, in un’ottica di valore di business (vedi figura 2).
In questo quadro, oggettivamente alquanto complesso, emergono comunque alcune cose che anticipano una vera data governance. Primo: le maggiori distribuzioni di Hadoop incominciano ad includere funzioni di data governance. Cloudera ha introdotto l’anno scorso il Navigator, che traccia, classifica e localizza i dati e li predispone a una ‘pulizia’ di base supportandone la trasformazione. Hortonworks ha recentemente rilasciato in Spark analoghe funzionalità, che includono anche la generazione di metadati e una tassonomia per tipi d’industria. Secondo: l’Apache Software Foundation offre alcuni elementi base con i progetti open source Falcon e Kerberos, che indirizzano sicurezza e life-cycle management. Terzo: alcune software-house indipendenti realizzano soluzioni di data governance, contribuendo a creare uno spazio d’offerta. Forrester porta ad esempio Datameer e Alteryx, i cui tool di discovery e analisi incorporano funzioni in grado di creare e organizzare data set in ambienti Hadoop e NoSQL.
Strumenti standard e strumenti ad hoc
Dal punto di vista dell’architettura delle piattaforme big data, la scelta degli strumenti di data quality e governance da applicare dipende essenzialmente dalle aree dove questi tool vanno ad agire sui dati. Che sono tre: le applicazioni business, o comunque relative all’operatività dell’impresa; il punto d’ingresso dei dati grezzi negli ambienti Hadoop e NoSQL (che Forrester chiama ‘landing zone’); le attività di analisi e data discovery.
La scelta di agire sulle applicazioni non presenta problemi architetturali perché queste possono usare i normali strumenti di data quality eseguendo i relativi processi all’interno dei cluster Hadoop tramite MapReduce e/o Spark. Eseguendo in parallelo ai processi Hadoop i modelli di controllo dati di Hive, HBase e HCatalog si hanno ottime prestazioni.
Per la ‘landing zone’ occorrono invece strumenti specifici pensati per Hadoop e NoSQl. Infatti mentre le soluzioni di data quality tradizionali possono contare su regole predefinite basate su una consolidata conoscenza dei dati, questi nuovi tool devono poter ridefinire i data model e gestire le ambiguità tipiche dei big data. Inoltre, spesso a questi strumenti è chiesto di poter elaborare dati in-memory (ancora con MapReduce o Spark) mantenendo un proprio repository dei metadati all’interno del sistema operativo di Hadoop. Forrester cita ad esempio un tool di data unification sviluppato da Tamr, in grado di elaborare contemporaneamente 100 milioni di record da 30 mila fonti con capacità di auto-matching che riducono del 90% gli interventi manuali per eliminare ridondanze e risolvere ambiguità.
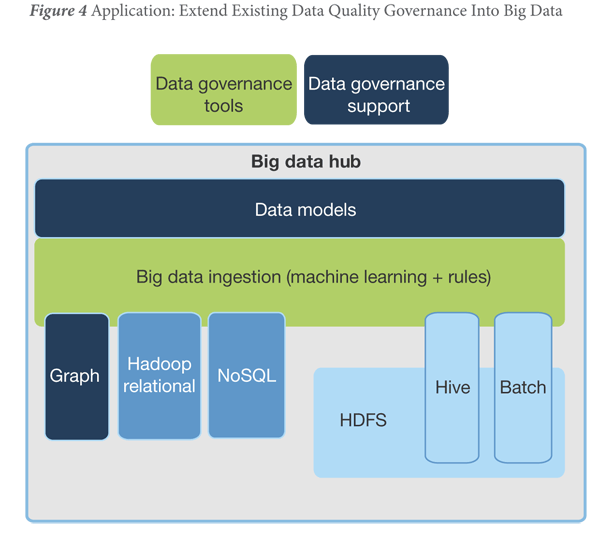
Quanto alle analisi, la loro natura impone un approccio del tutto diverso. Applicando gli strumenti di data quality ai punti d’ingresso o direttamente alle applicazioni si fa infatti una cernita ‘a priori’, senza sapere bene cosa tenere e cosa buttar via. In entrambi i casi si possono scartare metadati di valore ai fini di un approfondimento sul senso dei dati stessi. Se conoscere e scoprire ciò che accade e che potrà accadere è prioritario per il business, bisogna rinunciare alla data governance centralizzata e realizzare soluzioni self-service per dare gli strumenti di controllo sui dati direttamente a coloro che li devono studiare, data scientist o data analyst che siano. La figura 3 mostra un’architettura che appunto connette il big data hub alle big data analytics bypassando l’area della data governance.
Tre domande per finire
Si è visto come in un ambiente big data la qualità di dati vada affrontata in modo nuovo: Hadoop ha reso vaghi i confini tra storage e data warehousing; la tecnologia in-memory sposta la potenza di calcolo sul database e la struttura dati non è definita da dove questi stanno ma da come vengono interrogati. A questo punto, per impostare un’architettura di sistema ci si deve porre quattro domande. Prima: c’è una soluzione che può dare una qualità dati a copertura totale e definitiva? Aspettare che dall’offerta ne giunga una può richiedere troppo tempo. Conviene bilanciare costi e vantaggi su quello che c’è in una prospettiva di due-tre anni al più, senza pensare a un Roi nel classico medio termine dei tre-cinque anni. Seconda: come calibrare le attività di data quality? Se il controllo è troppo leggero si hanno dati scadenti (trash in…), se è troppo pesante si corrre il rischio di scartare dati che possono (o potrebbero un domani) servire al business. Diciamo che il ‘peso’ da dare dipende dallo scopo per il quale s’è implementato Hadoop. Se solo per potenziare l’EDW; se per far da area di transito e deposito per i dati in entrata, se infine per funzionare come enterprise data hub per le analisi.
Infine: come funzionerà la qualità dati con l’integrazione dei tradizionali Dbms e delle piattaforme big data (Hadoop e NoSQL) tramite data virtualization e con gli in-memory database? Bisogna trasformare il controllo sui dati da processo batch in servizio capace di invocare le quality rules in contemporanea all’aggregazione e al data streaming per le analisi in tempo reale. Non sarà facile, ma ‘s’ha da fare’.
| Le soluzioni di data quality sviluppate dai grandi vendor di software per l’impresa, oggi rappresentano una possibile transizione alla big data governance. Questi strumenti possono lavorare in ambienti esclusivamente big data così come in scenari ibridi comprendenti piattaforme tradizionali, dove Hadoop serve a potenziare il data warehouse esistente con dati di nuovo tipo (ad esempio, il comportamento dei clienti online). In questi casi i tool di data quality e master data management assolvono alle funzioni di snodo tra gli ambienti big data e quelli tradizionali. Per evitare carichi di lavoro che comportino picchi prestazionali, l’architettura del sistema può prevedere una base ridotta dei dati estratti. In tal modo, per esempio, un operatore di call center può avere dati storici relativi a un cliente senza dover muovere i dati sul sistema CRM ma eseguendo la richiesta di aggregazione su una ‘vista’ virtuale di Hadoop. |
















